VGGT读后有感
本人读完VGGT:Visual Geometry Grounded Transformer之后的感想喵
views
| comments
引言#
继写完SLAM3R的onlinee处理后,我又将目光投向了今年CVPR的最佳论文:VGGT:Visual Geometry Grounded Transformer ↗ 不要问我研究3R为什么不先看vggt😂,问就是我太摆了一开始懒得看了 。
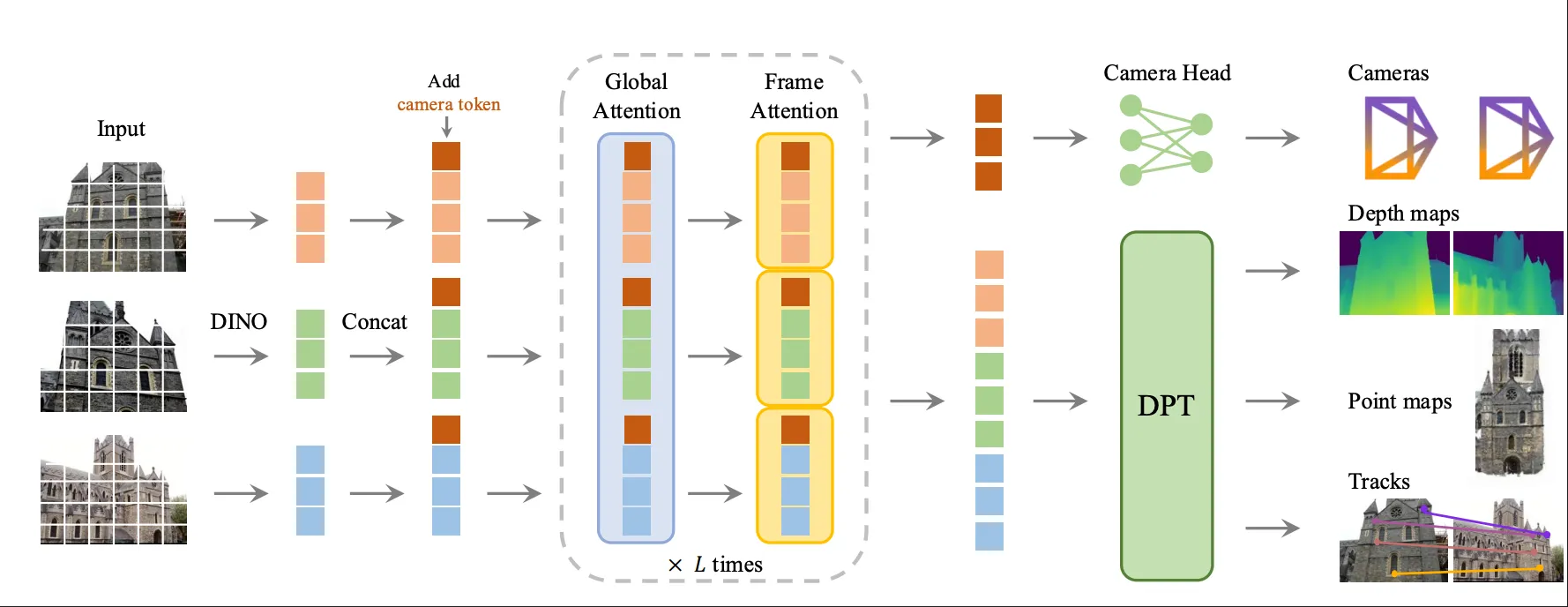
VGGT主要介绍了一个离线的多视图重建,位姿估计和轨迹追踪的强大的模型,与之前类似于SfM、DUst3R的重建方法相比,它的先进之处在于:
- 摆脱了这些方法所依赖的昂贵的后处理过程(而这通常没有计入到之前模型的性能评估中)
- 将多个任务:深度估计、位姿估计、视图重建、轨迹追踪等全部输出,表现甚至超过了之前单一领域的SOTA方法。
- 在将多个任务的结果全部输出的过程中,作者发现了引入不同结果之间的内在数学联系限制后会大幅提高模型的性能。
项目架构#
与之前的模块化解决问题不同,VGGT的主要结构是一个大的Transformer,它接受一个图片集作为输入,然后输出场景图片的不同三维属性。
值得一提的是,它所能解决的多视角三维属性几乎涵盖了三维视觉的方方面面:
- 相机位姿以及内参
- 点图重建
- 关键区域追踪
- 关于单张图片的深度图
并且,VGGT通过更加创新的举动,它将输出的多任务成果的内在几何关系作为归纳偏置整合进了模型,并发现了大幅度的性能提升,这个很值得去研究。
总结#
感觉VGGT就是一个巨大的transformer,通过极其暴力的手段解决问题,客观上来说,这确实展示了transformer在三维重建领域的应用,但其实我是有一些疑问的: 像自然语言处理这种工作,它是无法定量化去研究的,所以我们引入了transformer,似乎是用未知对抗不确定性的手段,但是,在这个三维重建这个领域,它真的有那么多不确定性吗? 还是感觉transformer对于三维重建的成果属于是结果能看,但是要达到更高的精度会让人很迷惑。