引言
经历了一些对未来选择的思考之后,最近在了解 mlsys 相关的内容,本文即为对 TP 的理解和总结,目前网上已经有大量的博文详细介绍了 TP 的实现细节,本文主要是为了自己未来查阅方便而写的文章,欢迎大家指正。
TP简介
Tensor Parallelism 是在 DP, MP 之后提出的一个方法,由 Magatrion-LM 首创。其出发点在于 DP, MP 仍然需要单卡在计算时凑齐一个完整的 layer 的参数和各种激活值、梯度、优化器状态,当一个 layer 过大的时候,单卡就放不下了。
而 Tensor Parallelism 将模型的计算拆成分布式的了,使得一层能够分布于不同卡上进行计算。
Transformer-like model
一个经典的 Transformer 模型的架构大致如下图:
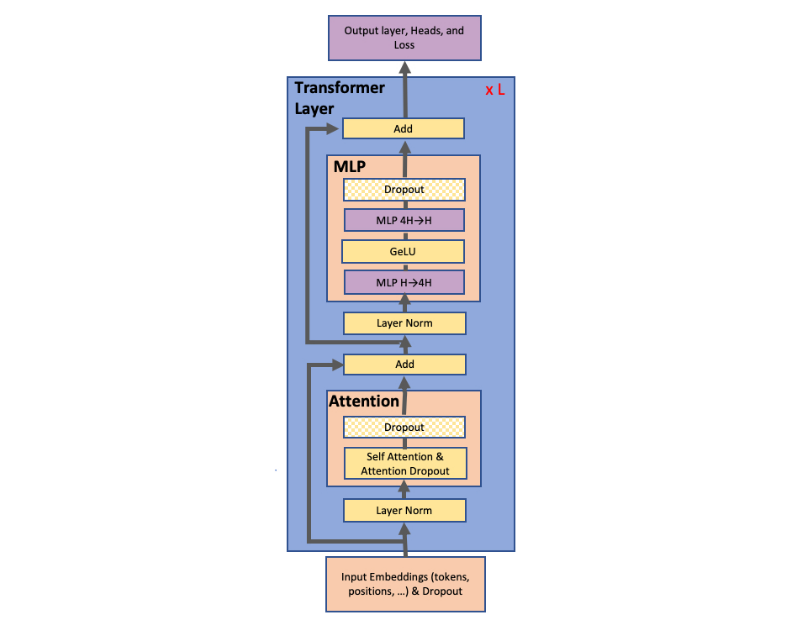
可以看到,一个 layer 主要由 Attention 和 MLP 层组成, TP 的关键优化点也就是在这两层上,下面将具体说明。
MLP
我们先从 MLP 层开始,简而言之,一个 MLP 层的数学描述大致这样:
其中:
一般来说,
我们先考虑不进行 TP ,仅仅进行单卡计算:
单卡forward
参数量:
计算量:
激活量:在 backward 里考虑。
单卡backward
首先对 dropout 反向:
这一步的 FLOPS 差一个数量级,可忽略不计,另外使用 表示 。
然后对 进行反向:
其中 。
这一步的 FLOPS 为
GeLU 的 FLOPS 几乎也可以忽略不计。
然后对 进行反向,几乎与 相同。
因此整个过程的 FLOPS 为 ,为前向传播的两倍。
然后我们从激活值占用角度分析,在没有梯度检查点的情况下,我们有:
1 | X (BS, d_model) use for compute L_W1 |
TP forward
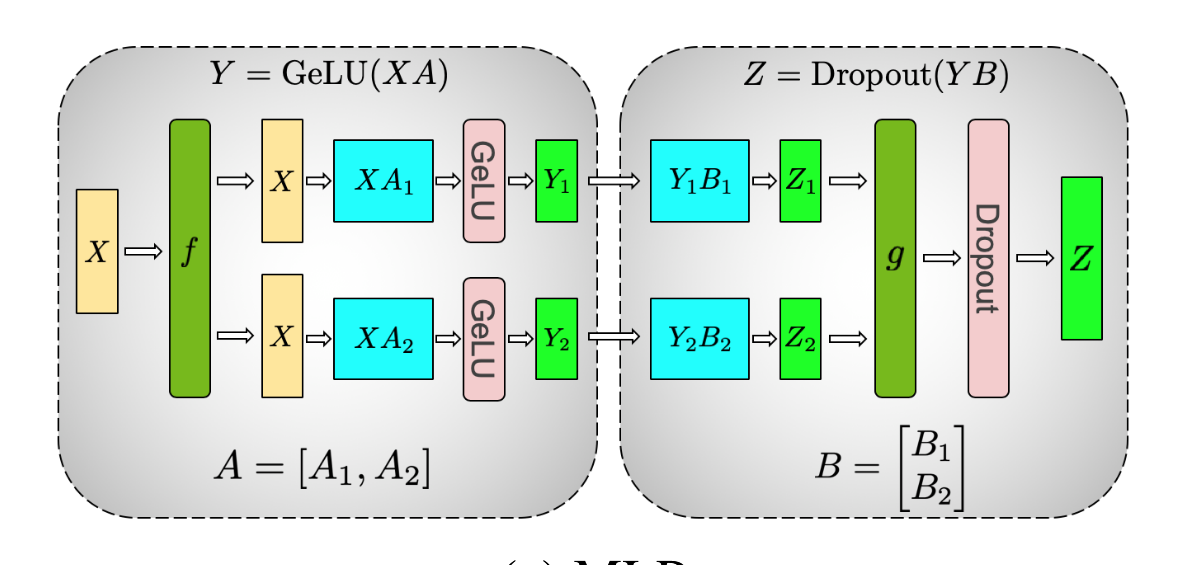
我们进行这样的切分方式:
1 | W_1 -> (W_11, W_12, W_13, ... W_1n) # W_1i: (d_model, d_ff / n) |
这样我们在输入 X 的时候全部注入,然后得到:
1 | H -> (XW_11, XW_12, XW_13, ... XW_1n) # XW_1i: (B, S, d_ff / n) |
值得注意的是,我们选择按列切分 使得我们得到的结果是可以独立通过 gelu 的,省去了这一步通信的麻烦。
之后考虑
我们选择将 进行这样的切分:
1 | W_2 -> [ |
之后,显然我们现在可以每张卡计算XW_11 @ W_21,而且他的形状就是最后矩阵的形状,
因此,我们算出来然后最后采用 all reduce 就可以得到最后结果啦。
ok ,我们现在对这整个过程进行分析:
- 参数量:
显然,我们现在把所有参数分散到了多卡上,而且分散均匀,
- 计算量:
但是这里还要考虑一个问题,就是最后 reduce-all 操作还要对所有激活值进行累加,但是这部分数量级过小,可忽略。
- 激活量:在 backward 里考虑。
TP backward
在每张卡上的前向是:
由于 AllReduce 之后每张卡上的 Z 完全相同,所以上游传回的梯度也完全一样,不需要额外通信。
此后,每一步的计算基本上与单张卡相同,但是要除以 。
因此,每张卡的反向 FLOPS 为:
然后,之后需要注意的是我们在反向传播的最后仍然需要一步 all-reduce ,因为我们此前计算的都是独立的梯度。
激活值的占用:我们有:
1 | X (BS, d_model) use for compute L_W1 |
Attention
单卡forward
输入数据:
1 | X (B, S, d_model) |
ok ,对整个过程清晰之后我们便可以分析其各个指标:
参数量:
通常来说这几个都相等,所以总参数为 。
计算量:
| 操作 | 形状 | FLOPS |
|---|---|---|
因此,总的 FLOPS 为:
需保存的激活值:
| Tensor | shape | num |
|---|---|---|
单卡backward
首先我们做 的反向:
加起来是
然后我们回到 :
这一步的 FLOPS 为 。
然后经过 Softmax 反向, FLOPS 可以忽略,然后计算 Q, K , FLOPS 为 。
之后对 做反向,权重梯度和输入梯度均为 ,共计为 12 。
因此,总反向 FLOPS 为:
为前向的两倍,所以我们在这里也可以认为反向传播的 FLOPS 为前向的两倍。
TP
显然这时我们就可以完全将 head 分到多张卡上,所有的几乎均乘上一个 即可。
但此时仍然需要注意的是,我们得到 O 之后仍然需要 all-reduce ,这与 mlp 是一样的。
先写到这里.