引言
更新,已决定停止更新( x
可以看到本文的 publishDate 是 4096-16-64, 实际上的 publishDate 是 2026-02-10 。
本文的初衷是一个长期更新的 3D recon 系列论文阅读,之前其实已经发过了一些该领域的论文的精读了,但是显然精读必然是不可长期持续的。因此,我想以本文——一个系列的形式记录对大多数论文的浅要阅读,当然如果有特别重要的论文,我也会单开一篇文章进行精读的。
本文的 cover image 是一个词云,记录了本文包含的工作的名称,希望它能不断地更新,成为一个 3D recon 领域的词云图谱。
CUT3R
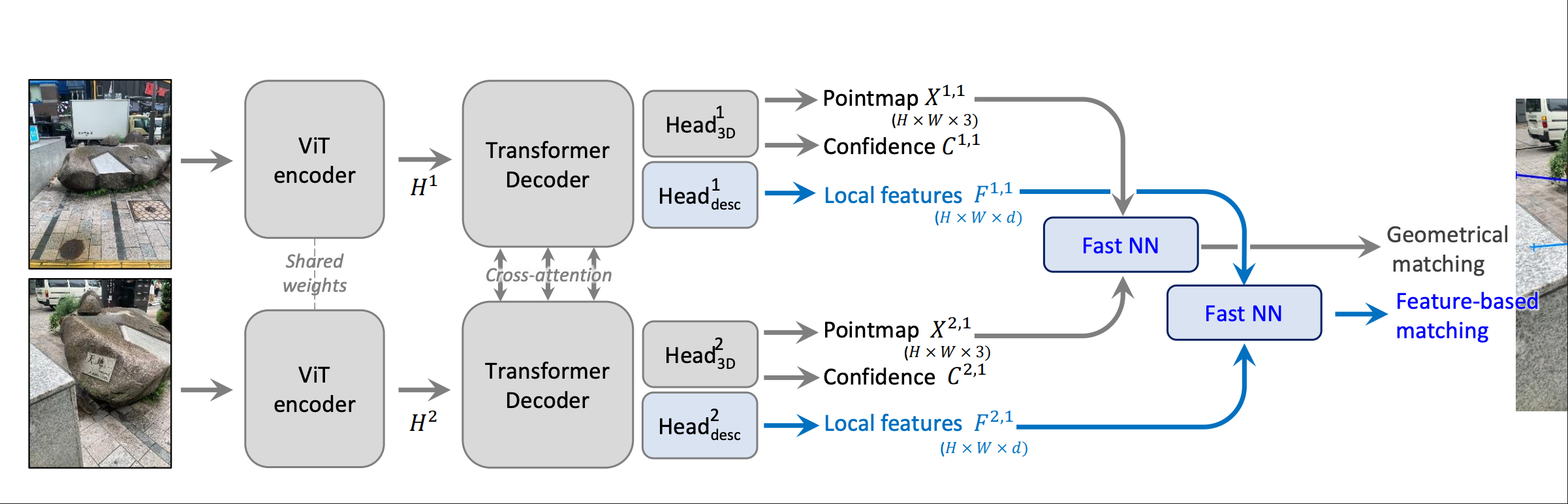
CUT3R 的输入是视频序列,但是也可以 unordered (据作者所言训练的时候是无序训练的,但是推理的时候推理的时候是 dataloader 先计算重合率来进行初步排序。),使用一个 feed forward 网络预测 camera parameters 和点云。
然后是一个 recurrent 模型,每一帧输入的时候添加一个 pose token 然后经过 encoder 和 decoder ,之后使用交叉注意力更新 和 ,之后再使用不同 head 来从和中提取 output 。
显然这样缺少修正,对于长序列容易造成偏移。但是作者似乎也提到了一个 revisit 机制,在输入结束之后拿着全局的来做之前的预测,在 7scene 上的 acc 和 comp 是有改善的,但是 NRGBD 不怎么明显。
此外,作者也说因为数据集质量的原因,采用的 head 即使已经有一个 pose head 和 local points head ,也仍然要加入一个 world ptshead (缺乏高质量的数据集)。
">
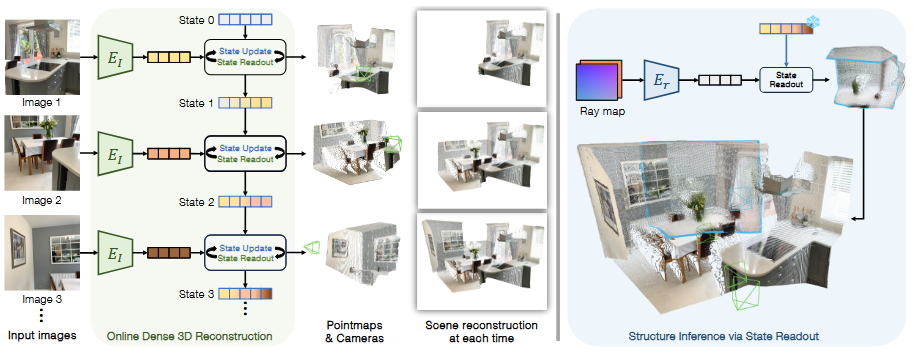
是一个相对来说比较有趣的东西,模型结构如下:
首先与之前的最大不同是它没有显式地选取参考帧和一个特定的 scale factor ,像 VGGT 就是先选取了一个 ref frame 然后做重建,但是重建质量受 ref 影响很大,因此选择了一个方案,就是一次性将所有帧全部输入,所有帧之间均平等,然后 inference 出一组相对位姿和局部点云,这样就能规避确定某一个 frame 作为坐标原点造成的不确定性问题。
但是仔细一想,仍然不怎么好避免一个 ref 的问题,首先,在一个 batch 内部,虽然我们预测的是一组相对位姿,但是直觉上感觉仍然是把某一帧与其他帧不融洽所导致的原先的那种大的,显著的,偶然性的损失转化为了现在的看起来不明显的、高一致的、所有帧都有的系统性损失。但作者通过实验证明了损失会变小,其实这也是比较好解释的,因为原先的可能是依赖,依赖……这种单向参考,而则进行了交叉注意力计算,仔细想来确实会更好。
其次,交叉注意力的复杂度大概是,显然对于长序列是不可接受的,作者训练和测试的时候均采用了有限个 batch 内 frame 的做法,但对于实际的长序列的话,感觉并不是很好做。如果切片进行拼接的话,显然也会面临 ref 的选择问题,但是这时候是一个 scene 之间的拼接,感觉确实会降低很多错误,如果分层做的话,也会降低误差,总之感觉似乎确实是一个不错的方案。
DA3
DA3 是字节 seed 的一个项目,可以说是力大飞砖,充分体现了工业界解决问题的规模( x 。
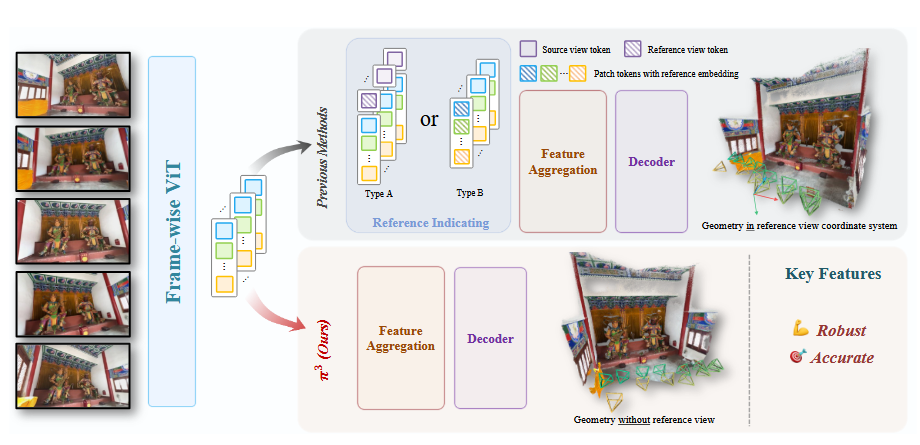
DA3 的主要创新点在于:
更简单的模型,作者的意思是 VGGT 即使结构很简单,但是由于其在 DINO 后接 AA 层的操作,因为 AA layers 是新训练的,因此过程中可能数据的利用率不高。而 DA3 选择了只利用 DINO 这一个方案,通过在 DINO 的层中变形数据完成了 AA 层所做的事情。因此, DA3 的几乎所有参数都是预训练过的,而 vggt 则有 的参数是从头开始训的,这是 DA3 的简洁之处。
预测任务的简洁性。相比于 VGGT 通过不同 head 得出了不同结果, DA3 则使用了一个更新的表达方式: Ray-depth 表达,具体来说就是使用一个 Dual head 来分别输出一个像素的深度信息和光心与之相连的射线的信息,从而天然地同时包含了点云和 pose 信息,而且在设计 loss 的时候是可以加入一致性信息的。相比与 vggt ,这似乎加强了一致性,也提高了数据利用率,感觉 pose 和 pts3d 反而是不容易加入一致性的,作者做的消融实验也证实了这一点。
使用 teacher 标定数据,首先训了一个 teacher 模型用于给深度不好的 frame 重新生成 depth ,之后依照这个 depths 训练。感觉最终效果也很依赖这个 teacher 模型。
但是, DA3 的弊端也有一些,他的效果确实非常好,但是阅读之后才发现他是用 128 x H100 训练的,这个规模确实有点难以复现。小算力情况下上面两条结论似乎很有帮助,可以尝试。
MapAnything
首先是 Meta 的项目,和 VGGT 难道不构成什么竞争关系嘛()
主要创新点在于他的输入很有意思,不同于 VGGT 还有以往的重建工作只输入图像序列, MapAnything 支持多种多样的输入,对于每一个输入都会通过一个 encoder 最后对齐到 DINOv2 输出的 image token 上,然后就是正常处理的流程,不过似乎它多加了一个 scale token ,用于预测 scale 信息。
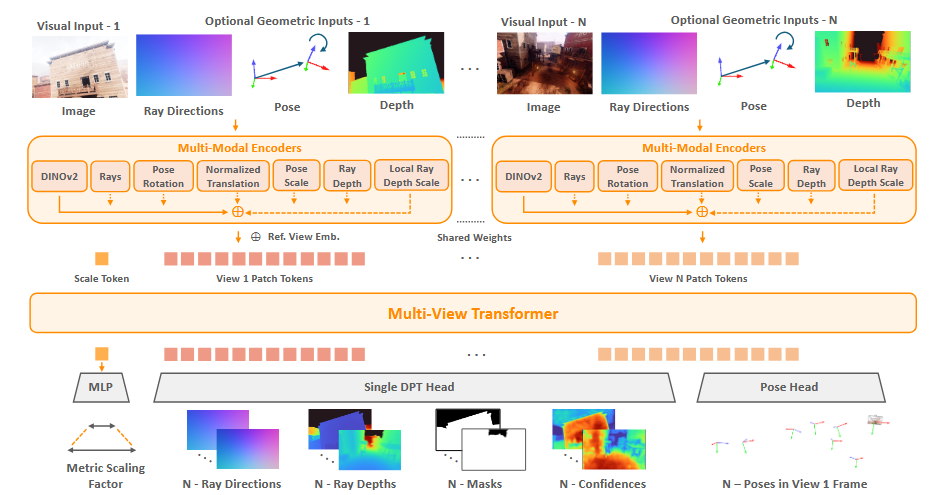
感觉其利用了 nlp 里面的多模态,证明了给定不同类型的输入其预测的准确性与相应的专家模型性能相似,这是很有价值的,因为他减少了很多训练量(虽然也是在 64xH200 上训了 10 天)。
另外一个比较有趣的地方在于,他最后的点云数据不是直接输出的,而是由 depth , ray , pose 联合输出,这解耦了 VGGT 的冗余预测模式,而且在设计 loss 的时候能保持更好的一致性,感觉这个跟 DA3 输出 Depth-ray 的做法还是很像的。
不过其缺点也非常明显,首先对于长序列情况下,其仍然没有摆脱的处理复杂度;其次模型是 offline 的,不过感觉各有各的应用场景;最后就是推理速度和显存占用,推理速度在 100frame 的时候就已经接近 10s ,而且这时的显存占用也已经来到了 65G 左右,即使采用了作者提出的 Mem Efficent 策略,即在 dpt 头采用串行计算策略也是 20G 左右,似乎有点太大了( x
此外,作者表示了在输入过程中模型无法对噪声数据进行处理,也就是说潜在的噪声可能会污染整个 transformer 的内容,另外融合时机是在 encoder 之后进行,而且是简单的相加,可能有更精细的融合方式。
AnySplat
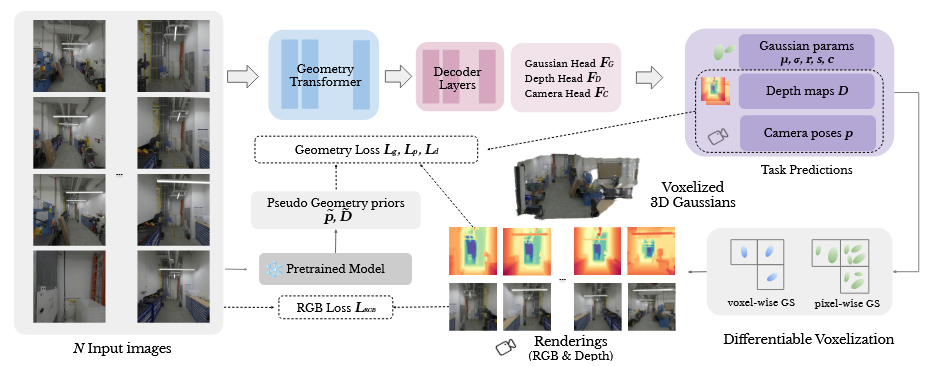
与之前讲过的大多数点云重建的工作不同, AnySplat 是 3dgs 重建。具体来讲就是他在 vggt 的基础上进行改造, backbone 与 vggt 相同,但其 head 则是一个 gaussian head, 一个 depth head ,还有一个 Camera head 。然后通过一个可微体素化将原本稠密的高斯球聚合到一起,训练的时候则监督:
每一帧位置的 rgb loss
depth 的深度与 gaussian depth 的差异损失
相机参数与 vggt 预测出的损失
模型预测深度与 vggt 之间的深度差异
首先, 2 的 loss 保证了其几何一致性,也就是让不同视角的深度尽量保持一致,可以避免分层现象。此外,文章作者说他们实现了一个 Differentiable Voxelization ,可以有效解决生成的稠密高斯球产生的复杂度问题。
总体来说,这是一个高度模仿 vggt 的工作,只不过换了一下 head 和输出形式,其余部分都差不多。此外为 offline 的重建,看上去速度似乎还可以,但是同样面临长序列问题。另外,固定世界坐标系为第一张图片,去监督每一个绝对位姿是否正确,似乎也是存在所述的归纳偏置问题的。
RayZer
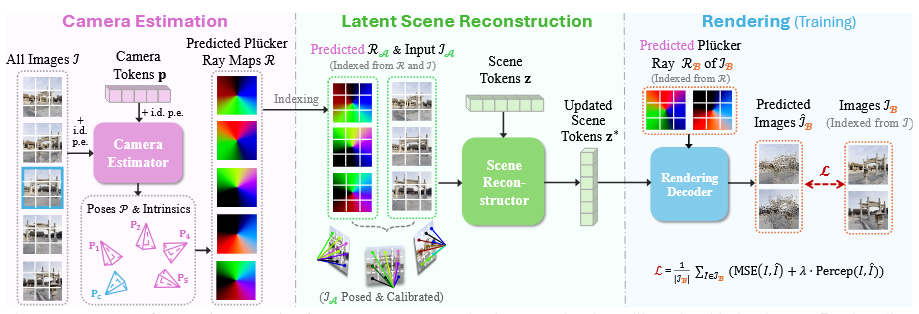
令人耳目一新的自监督模型,训练过程只需要图片而不需要 gt 的 pose 和内参,训练过程大概是这样的:
首先输入张图片,将其分为 和两个集合。
然后模型通过 Camera Estimator 模块,预测出 pose 和 intrinsics 。
之后对于 ,模型根据其对应的预测出来的 和本身的图片输入,生成场景的 token.
然后对于,模型选择通过和 预测出 然后监督 与 之间的损失,然后更新所有的值。
因此,推理时的大致步骤大概就是先把场景的已知几张图片输入得到 ,之后针对一个特定的 pose ,计算一个光线图,之后输入到 rendering decoder 里得到在这个特定的 pose 下的 rgb 图片。
感觉和 nerf 好像,都是一个隐式的表达整个场景,不过不同的是 RayZer 是一个更直接的模型,图里的三个模块每个都是 8 层 naive transformer , loss 仅由最后的 rgbloss 和 LPIPS loss 决定,感觉挺聪明的。不过感觉 rendering 部分采用的表现形式——类 raymap 形式似乎真的挺好用的。
另外,值得注意的是第一部分,在预测 pose 和 intrinsics 时,直接选取了中间帧作为参考帧,使得模型能跨越更长的距离。此外,如果说我们在第一部分就引入 ,能否实现定位功能?不过作者似乎做了消融实验,发现在训练的时候,从图像特征中提取几何关系比从一个未成形的 中提取容易得多。但是我觉着可以在 rendering 部分再添加一个 decoder 用于定位。
另外,这个模型完全打败了 LVSM (一个有监督的模型),感觉是一个非常惊艳的工作,看项目主页的 demo 视频感觉真的很不错啊。
Spa3R
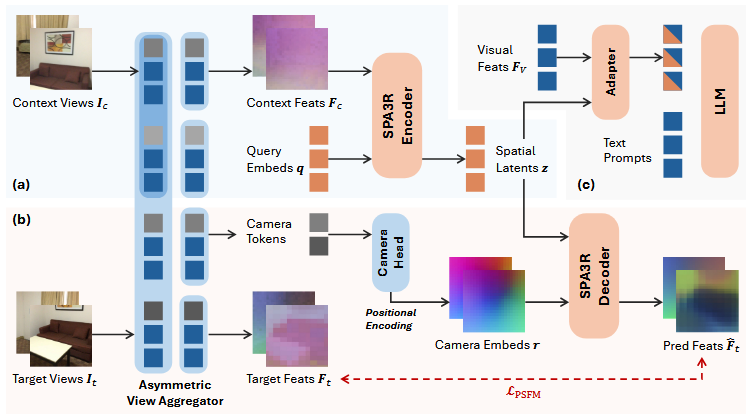
首先是一个自监督的模型,模型的 backbone 设计的有点复杂:
我们给出一个场景的 views ,然后将 views 分为 context view 和 target view ,首先将所有 views 通过一个改造过的 vggt (似乎是只引入了 head 之前的部分),改造内容是在 context Views 的 AA 层那里把 Target Views 给 mask 掉,然后得到 Context Views 的 feature 和 Target Views 的 camera token 和 Feature ,之后,数据流向两条路径:
Context views : 与一组可学习的 通往 Encoder ,然后得到 作为空间的隐式表征。
Target views : camera tokens 通过 camera head 生成 camera embeds ,然后与 一起输入到 Decoder 里生成对 Target views 的预测过的 feature ,然后将得到的预测 feature 与 进行监督得到 loss 。
推理的阶段我们就只看 Context Views 得到的 ,将与 qwen2.5 vl 得到的 输入到一个Adapter里,然后将这个 adapter 和 text prompt 输入到 llm 里得到最终结果。
首先,肉眼可见这项工作把大量的其他工作缝合到了一起, Target View 阶段用了 DINOv3 和 VGGT , 的后续处理用到了 qwen2.5 vl ,但是这篇文章叫 Spa3R 啊, Dust3R 被放到哪了呢?然后可训练的内容只有 Encoder 和 Decoder ,仅 6 层 Transformer ,而且通过两个作为 loss 进行训练,训练结束之后即丢弃 Decoder ,保留训好的 Encoder 和 q 。然后后续还有一个针对 Adapter 的一个微调,让其学到怎么生成一个合理的融合 。
模型做了几个消融实验:
Target Views 阶段作者证明了同时使用 VGGT 和 DINO 会更好(包含语义和空间信息),这是一个比较显然的结论。
提取出一个场景 表征是一个更好的手段,相对于现有的几个类似于 VG-LLM 简单把所有特征输入到 llm 里效果更好(但是只提升了 3 个点,感觉有点低于预期,考虑到第二阶段训练只进行了 1 个 epoch ,有没有可能是训练量不够?我也是第一次读 VLM 相关的文章(),不过看具体的比分, Multi-Choice 涨分了,而 Numerical 几乎没变,确实是 make sense 的)。
pose embedding 的影响, PRoPE 比 plucker 更好。
Mask Ratio ,这也是一个比较显然的消融实验。
Adapter 使用提高了点数,比较 make sense 。
模型只在 ScanNet 和 ScanNetpp 上进行了 pre train ,使用了 8 张 5090 进行训练,在 VSI-Bench 上达到了 58.6 的水平,超过了之前的大部分 model ,查看现在的 VSI-Bench Leaderboard ,其性能也是处于前列的(不过论文里的表格好像有些数据有点不对?可能有更新吧)。算是为领域开了一个新坑(),自监督看上去也不错()。
看上去这篇文章正在投 CVPR ,是笔者写阅读笔记的两天前才登上了 arxiv ,也不知道中没中,方法是很有趣
Spann3R
结构很复杂,首先大部分模型权重继承自 Dust3r ,然后模型的 backbone 大致如下:
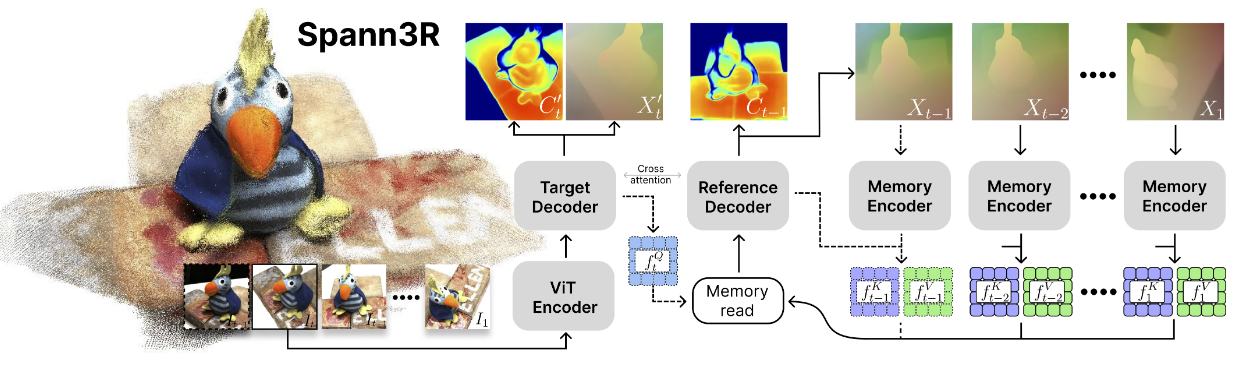
预编码 :首先将一帧输入到 ViT Encoder 得到一个 ,此时我们手上还有一个上一帧的 。
查询记忆: 根据 ,我们可以从历史记忆中查询出一个 来作为下一步的输入。
主要推理部分: 之后我们将这两个 feature 输入到 Target Decoder 和 Reference Decoder ,这两个 Decoder 会做 self attention 和 Cross attention 然后分别得到 和
Heads : 对于 ,在推理阶段我们会使用一个 query head 来提取出,然而在训练阶段我们也会加入一个 head 将其转化为点云和置信度来监督训练;对于 ,我们会通过一个 reference head 将其重建出点云和置信度。
记忆: 之后,根据和 ,我们将其通过一个 Memory encoder + MLP head 生成一个 ,然后根据这个和点云通过一个 Memory Encoder 生成 ,之后会对已有记忆去重, 如果工作记忆已满剩下的就会进长期记忆然后做进一步处理。
这是一篇 24 年的文章了,主要创新点就在于他改良了 Dust3R ,使得可以对多个图片输出一个一致的全局坐标系下的点云,此外使用记忆方法,分层处理记忆。
但很显然的是,虽然该方法加入了记忆,但是记忆看上去也是近期记忆的方案,客观上因此而存在长距离漂移的现象,此外,如果遇到 reloop 现象,记忆是否能健康提取也会是一个比较大的问题。
做的消融实验大致有这几个:
关于记忆方面的消融实验,去掉长期记忆会引起很大的漂移现象,而注意力不截断的话也会引发噪声的干扰
关于长期记忆应该取多大:作者发现 1000-2000token 的过程中漂移得到极大修正,但是 4000+之后就不会有明显的提升,因此最后作者选择了 4000.
Dust3R 采用了 exp confidence function ,本文将其改为了 sigmoid ,事实证明是有所改善的。
Flow4R
一个局限性很大的三维重建追踪方案,不过在表现形式上很有新意。
模型的 backbone 很优雅,首先接收两张图片作为输入,通过共享权重和 cross attention 的两个对称 encoder-ecoder-head 结构得到每张图的 其中, 是相机坐标系下的点云, 是一个场景流,描述每一个像素如何从本张图片移动到下一张点云,之后还有一个 指示哪个像素在求解 pose 的时候最可靠,最后的 是全局的置信度。
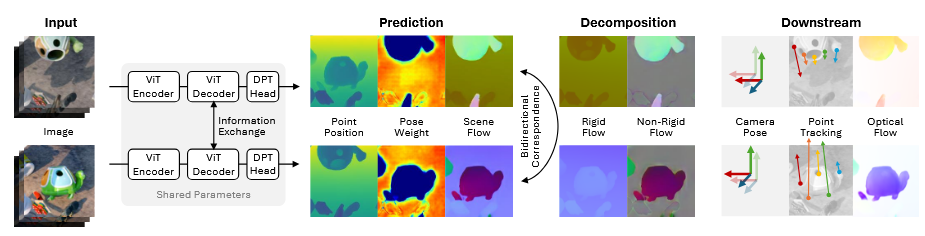
得到这些元素之后,可以首先将 pose 通过最小二乘法求出:
是由 得到的,得到 pose 之后就可以做位姿流和场景流的分解,然后很多下游任务就可以进行处理了。
针对于长序列数据,作者提出了将第 1 张 frame 作为锚点,后续的每一张都与之输入处理,好处是可以通过 L2 norm 来归一化尺度,但是坏处也非常明显,一是稍微长一点的序列,就会出现遮挡现象,模型目前来看没有一种很好的应对方式;二是极其依赖第一张 frame 的质量,鲁棒性不算太好。观察其论文里呈现的 demo ,看起来也通常是对一个角落 or 一个相似视角区域做的重建,完整场景重建效果存疑。
此外,作者竟然只做了一个消融实验(能中吗?)对比了三种不同的网络预测和监督变体 :
预测场景流 ,并用真实的 进行损失监督 。
预测场景流 ,但用目标帧的真实 3D 点位置 进行监督 。
直接预测目标帧的 3D 点位置 ,并用真实的 监督(场景流则通过简单的减法推导: ) 。
消融结果:实验证明,直接预测并监督 的性能最佳 。因此后来直接预测的实际上是
总体来说,这篇工作证明了一点,可以通过引入流的方式来完成 Dust3R 这种结构从静态到动态的拓展,但确实局限性很大。
这项工作似乎还没有开源()
AMB3R
把三维体素引入到了重建中,使得模型能够真正地从空间角度来考虑重建任务。简而言之就是之前的重建采用的 ViT 将图像分为一个一个 patch 造成隐式几何中缺乏空间紧凑性约束,于是论文作者想了一个办法把空间紧凑性加入到了 backbone 当中。
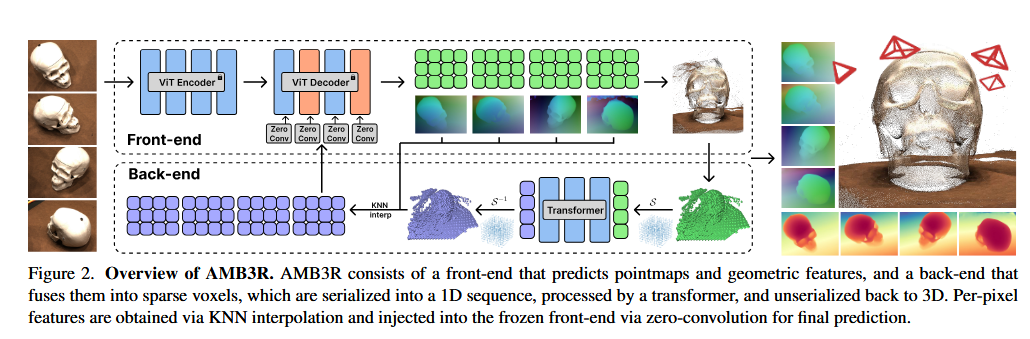
大致的 backbone 分为前端和后端,其中,前端继承了 VGGT 的网络和参数,一张图片进入之后会经过 Encoder 得到一个初步的 feature ,然后数据的主题是向 decoder 移动,但是这部分 feature 也会使用一个 scale head 预测一个绝对尺度。
然后,进入 decoder 的 feature 会对 keyframes 做 cross attention ,这里的 keyframe 就可以理解为场景的隐式表达,经过该过程之后, decoder 就会输出一个 pointmap 和一个 confidence ,在推理阶段,之后会有一个门控机制:如果置信度足够高,那就直接进入下一阶段,反之则会将点云和 feature 变为体素,然后通过一个 point transformer 优化该体素的 feature ,之后再会逆变换变为 2Dfeature ,之后我们会将该 feature 注入到前端的 decoder 中,重新拿到一个高级的点云。
然后我们拿到了当前帧的点云以及物理尺度,然后系统会将该结构放大/缩小,然后根据 keyframes 和 VGGT 预测出的 pose 将该结构拼接到大的全局点云中,最后我们会评测该点云是否可以成为 keyframes ,然后将其处理掉。
将体素引入到点云重建里很厉害,作者做的几个消融实验:
移除了基于 sparse voxel 的后端,转而使用一个 2D 做 alternate attention 的后端,发现精度不如之前。
去除了零卷积机制,发现模型短时间内根本就未收敛。
在算 loss 的时候去除了 scale 发现效果变差,也就是说模型需要去专注思考几何结构。这是在训练阶段做的事情
这篇文章的训练成本非常非常的低,依赖于一个已经训好的 VGGT ,只训练了微调点云特征的一个 point Transformer 和一堆 head ,感觉非常有启发性非常厉害,同时也中了 CVPR2026 ,符合预期(似乎是 Spann3R 的续作)
VGGT-SLAM
我说这是一篇数学论文,文中没有训练任何模型,仅仅是介绍了一种局部点云拼合办法。
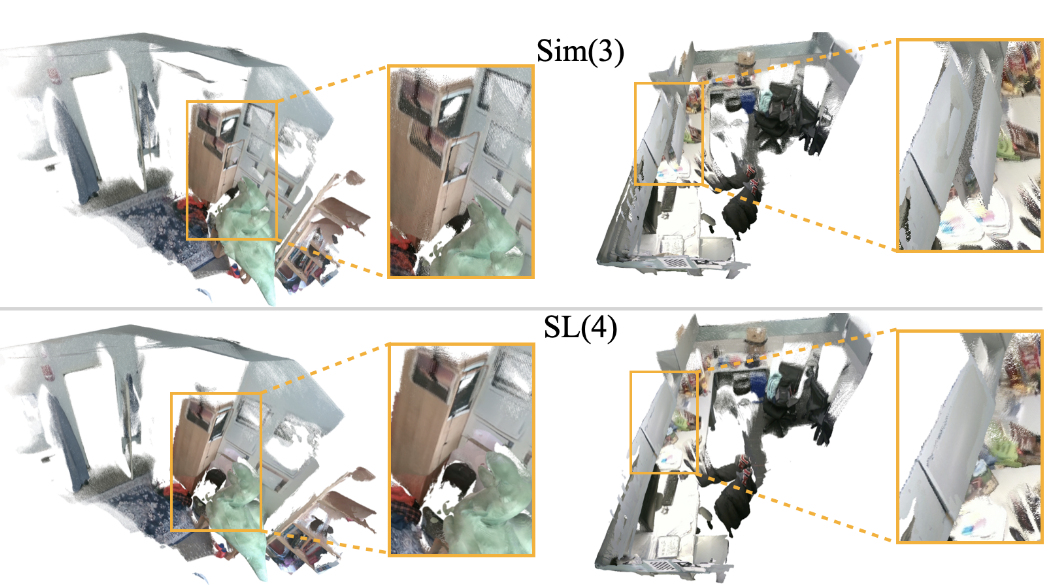
顾名思义,这篇工作基于 VGGT 输出的点云和 pose ,作者认为 VGGT 预测出 pose 和局部点云之后直接进行 Sim(3)变化为全局点云是有问题的,主要灵感来自于传统 CV 里面的双目立体视觉:相机之间的单应性矩阵或者说是本征矩阵并非仅仅包含了 pose 中进行的旋转、平移,更有一些拉伸,透视等等等。具体来讲就是 VGGT 预测出的点云深度包含了相机的射影形变,直接使用 Sim(3)方法来还原是不准确的。
因此,作者转而使用了 SL(4)进行点云的对齐,具体来讲,当 VGGT 得出了点云和 pose 之后,会进行以下几个操作:
对于一个子地图里的帧,作者选择相信 VGGT 的质量,作者在代码里设置了一个 submap_size 参数用于控制子地图的大小。
对于不同子地图之间,因为我们想得到一个在不同坐标系下共享的三维点,所以作者这里采用了一个很聪明的办法,将上一个子地图的最后一帧重复输入到下一个子地图里,这样 VGGT 的输出就包含了相同图片在不同坐标系下的点云,由此可以建立点与点之间的对应关系。
之后根据传统的一些算法,可以计算两个子地图之间的 SL(4)矩阵,到这里第一步就算完成了
下一个步骤就是全局对齐,作者也写得太数学了吧:
具体来讲,作者构建了一个基于最大后验估计的非线性因子图,目标是最小化所有子地图之间的相对单应性误差:
$\hat{H}=argmin_{H\in SL(4)}\sum_{(i,j)\in\mathcal{L}}||Log(H_{i}^{-1}H_{j}(H_{j}^{i})^{-1})||{\Omega{ij}^{H}}^{2}$
然后引入各种优化器,这里我的数学太烂了( x )根本看不懂,只知道他是需要迭代优化的。
嗯嗯,所以这样我们就可以得到一个后端,对于每一个子地图,都给出了一个将其变换到潜在全局坐标系下的 SL(4)矩阵,从而消除了 Sim(3)变换带来的问题。
此外,文章还提出了一种 reloop 机制,就是说在一个子地图待输入的时候,系统会利用 SALAD 描述子去寻找历史子地图中是否有相似的图片,若有,系统就会选择将那张图片作为共享帧,我们这时候就会有多个相对的信息。
总体来说,这篇工作就是提供了一个偏传统的对齐方法,比较优雅,但是很显然缺点也很明显,首先对于单个子地图,该工作完全信任 VGGT 的输出结果,缺乏鲁棒性;其次,其得出对齐是通过迭代优化得出,相对于直接拼接会慢上很多,另外有太多的查询操作(如 reloop ),感觉复杂度还是有点高的。
不过可以从上图看到,他确实改善了点云拼接时可能产生的分层的质量。但是,查看其 github 里的 issue ,似乎稳定性存疑:
Due to potential randomness in our approach caused by RANSAC, we report the average performance over five runs, which have a low spread (small standard deviation) as shown in Sec. 5.5.
而且那个 issue 到最后作者都没有回答,感觉有点尴尬( x