引言
mesh construction 是我刚刚开始了解的一个方向, 今天读了SF3D: Scene Fusion for 3D Reconstruction with Transformers这篇论文, 本文笔记记录用于后续翻阅学习。
读完这篇论文之后, 感觉 mesh reconstruction 与 point cloud reconstruction 还是有很大区别的, 尤其是这篇文章中引入的几个新的 mesh 专有的 module, 感觉要比 point cloud reconstruction 更加复杂一些.OK,
废话不多说, 直接进入正题.
Introduction
作者一上来就提出了几个 issue:
- Light bake-in: 现有的模型将光照信息直接 bake 到 texture 里, 使得生成的 mesh 难以利用, 而在 SF3D 中, 作者提出了使用 explicit illumination 和一个不同的使用 Spherical Gaussian 的 shading model 来解决这个问题(如上图第一行所示).
- Vertex Coloring: 现有的工作中, 生成的 vertex 的数量过多, 使得性能开销很大. 作者认为一个关键问题就是 UV unwrapping 的额外处理时间, 于是作者提出了一种 highly parallelizable fast box projection-based UV
unwrapping method 来解决这个问题(如上图第二行所示), 这使得时间从 10-30s 减少到了 0.5s, 而且从图上来看, 细节比 baseline 的 TripoSR 的效果更好. - Marching Cube Artifacts: feed-forward network 通常生成类似与 Triplane NeRFs 的体素网格, 然后使用 marching cube 来提取 mesh, 但是这种方法会引入一些 artifacts,
作者提出了使用一个对高分辨率 Triplane 更有效的 architecture, 并且使用 DMTet 来对生成的 vetex diplacement 和 normal map 生成最终的 mesh, 这样可以有效减少 marching cube 引入的 artifacts(如上图第三行所示). - Lack of Material Properties: 现有的工作生成的 mesh 在不同光照下都会看起来 dull, 这是因为缺乏 explicit 的 material properties.为解决这个问题, 作者预测了 non-spartially varying material properties
(如上图第 4, 5 行所示).
通过以上的改进, SF3D 可以从单张图像生成高质量的 mesh, 且生成的 3D 资产体积小(1 MB)并且可以在 0.5s 内生成.
Method
为了解决上面提到的问题, 作者提出了 SF3D.
首先, SF3D 是在 TripoSR 的基础上进行改进的. TripoSR 训练了一个能够生成 Triplane 3D representation 的 transformer. 它使用 DINO encode image, 然后把 token 送入 transformer 中, transformer 输出一个分辨率的
triplane, 然后 triplane feature 之后被 decode 为 color 和渲染成标准 NeRF. TripoSR 只学到了 colors 并且不能处理反射等材质属性.
Overview
SF3D 的整体架构如下图所示: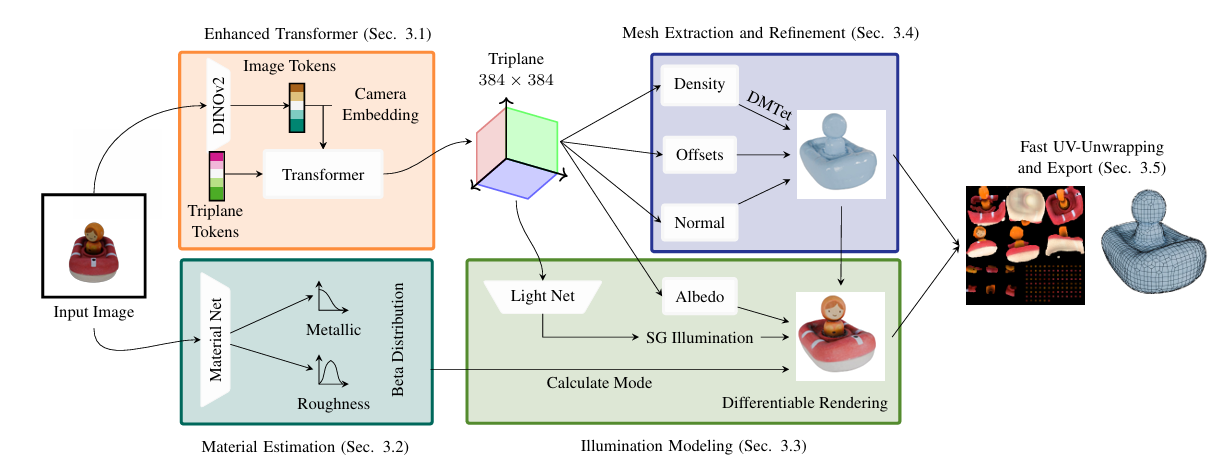
可以看到, SF3D 由 5 个主要模块组成:
- Enhanced Transformer: 用于预测高分辨率的 triplane feature.
- Merterial Estimation: 用于预测材质属性.
- Illumination Modeling: 处理光照问题.
- Mesh extraction and refinement: 用于从 triplane 中提取 mesh 并进行细化.
- UV Unwrapping and Export: 产生 low-poly mesh 和 高分辨率 texture map.
Enhanced Transformer
为了生成高分辨率的 triplane feature, 作者对 TripoSR 的 transformer 进行了改进, 主要有以下几点:
- 首先, 作者将 DINO 替换成了 DINOv2, 这样可以获得更好的 image feature.
- 其次, 作者对 triplane 导致的 aliasing 问题进行了讨论

如上图所示, 低分辨率的 triplane 会导致 aliasing 问题, 但是简单地提高 triplane 的分辨率会导致模型更复杂, 作者说, 他从 PointInfinity 中获得启发,
(PointInfinity 提供了一个不需要计算 triplane 的 self-attention 的架构), 因此, 作者将分辨率提高到, 从而降低了走样.
Material Estimation
SF3D 输出了 metallic 和 roughness 两个材质属性. 论文中提到, 理想状况下, 人们希望材质属性是 spatially varying 的, 但是这样并不现实. 于是作者简化了这个问题, 为整个物体
预测这两个属性, 作者提到虽然这种非空间变化的材质属性通常适用于同质物体, 但是实际上能显著改善渲染效果.
为了实现这个预测, 作者引入了一个 Material net, 首先将图像通过 CLIP encoder 编码, 然后通过 2 个 MLP 预测 metallic 和 roughness.
Illumination Modeling
作者提出要显式 estimating 光照, 如果不这样做的话, 输出的 RGB 颜色会将光照信息 bake 进去, 使得生成的 mesh 难以利用. 为此, 作者提出了一个 Light net, estimate SG 光照. 因为 triplane encode 了场景的几何信息, 所以可以能够推断光照变化.
具体实现上, 作者使用 Transformer 输出的 分辨率的 triplane 作为输入, 使其通过 2 个 CNN 层, 接着进行 max pool,
最后通过一个 MLP 。 Light Net 输出 24 个 SG 的 grayscale amplitude values, 并使用 Softplus 以确保值为正数。这些 SG 的轴和锐度值保持固定, 其设置旨在覆盖整个球体。
利用这些振幅值, 作者实施了一种类似于 NeRD [4] 中使用的 deferred physically based rendering 方法.
此外, 作者的方法在训练阶段还引入了一个 lighting demodulation loss , 该损失函数旨在确保:一个具有 entirely white albedo 的物体上的光照,
能与输入图像的亮度紧密匹配。 lighting demodulation loss 强制学习到的光照与训练数据中观察到的光照条件保持一致.
这可以被视为一种 bias, 用于解决 appearance 和 shading 之间的 ambiguity.
Mesh Extraction and Refinement
为了从 triplane 中提取 mesh, 作者使用了 DMTet. 作者提出了两个 MLP head 来预测 vertex offsets 和 vertex normals. 这里受 MeshLRM 启发, 作者也单独使用了分离的 decoder MLP 来辅助这两个 head 的训练.
作者发现, vertex offset 能够反走样, 而 vertex normal 则能提升细节表现. 鉴于一开始 normal map 的预测不会太准确, 于是作者使用了 slerp 来稳定训练, 这是在一开始的 5K step 里发生.
然后引入了各种 loss 来训练这个 mesh extraction and refinement 模块:
- $$\mathcal{L}_{\text{Nrmconsistency}}$$: 法线一致性损失
- $$\mathcal{L}_{\text{Laplacian}}$$: Laplacian 平滑损失
- $$\mathcal{L}_{\text{Offset}} = v_o^2$$: 顶点偏移正则化
- $$\mathcal{L}_{\text{Nrmrepl}} = 1 - n \cdot \hat{n}$$: 法线复制损失
- $$\mathcal{L}_{\text{Nrmsmooth}} = (\hat{n}(x) - \hat{n}(x + \epsilon))^2$$: 法线平滑损失
UV Unwrapping and Export
SF3D 模型的最终阶段是一个高效的导出流水线, 关键挑战在于传统 UV 展开的计算密集性, 这不符合快速生成的要求. 为此, 作者提出了一个基于立方体投影的展开方法. 该方法利用网格面法线独立决定投影方向, 实现了可并行化的展开过程.
具体实现上, 该方法执行 2D 三角形-三角形相交测试来处理 UV 图集中的遮挡, 并根据深度和接近度对相交面进行重新分配. 同时, 通过遵循径向 切线方向旋转 UV 岛以最小化阴影接缝. 接着, 通过 UV 展开将世界坐标和占用率烘焙到 UV 图集上
, 用于从 triplane 中查询反照率和表面法线. 为防止接缝伪影, 作者采用了一个迭代过程, 使用 部分卷积和最大池化来扩展 UV 边界, 确保纹理平滑向外混合.
之后, 作者将所有文件作为 glb 格式导出.
Overall Training and Loss Functions
由于直接在网格渲染任务上训练方法会产生不满意的结果, 作者首先在 NeRF 任务上进行了预训练. 完成预训练后, 模型过渡到网格训练,
将 NeRF 渲染替换为 differentiable mesh rendering 和基于 SG 的着色.
分步的损失函数如下所示:\begin{split}\mathcal{L}<em>{\rm render}&=\underbrace{ \lambda</em>{\rm MSE}}<em>{ 1 0}\mathcal{L}</em>{\rm MSE}+\underbrace{ \lambda_{\rm LPIPS}}<em>{ 2}\mathcal{L}</em>{\rm LPIPS}+\underbrace{\lambda_{ \rm Mask}}<em>{ 1 0}\mathcal{L}</em>{\rm Mask}\ \mathcal{L}<em>{\rm mesh}&=\underbrace{\lambda</em>{\rm Laplacian }}<em>{ 0.01}\mathcal{L}</em>{\rm Laplacian}+\underbrace{\lambda_{\rm Nrm Consistency}}<em>{ 0.001}\mathcal{L}</em>{\rm Nrm consistency}+\underbrace{\lambda_{\rm Offset}}<em>{ 0.1}\mathcal{L}</em>{\rm Offset}\ \mathcal{L}<em>{\rm shading}&=\underbrace{\lambda</em>{\rm Nrm repl}}<em>{ 0.2}\mathcal{L}</em>{\rm Nrm repl}\underbrace{\lambda_{\rm Nrm smooth}}<em>{ 0.02}\mathcal{L}</em>{\rm Nrm smooth}+\underbrace{\lambda_{\rm Demod}}<em>{ 0.01}\mathcal{L}</em>{\rm Demod}\end{split}
总损失为:
Results
作者在 GSO 和 OminiObject3D 数据集上对 SF3D 进行了评估. 结果如下图所示: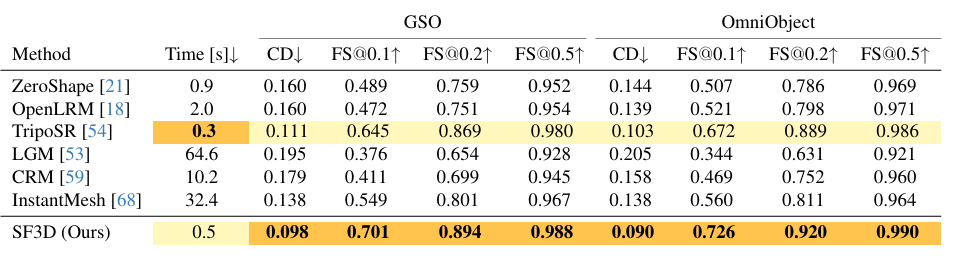
可以看到, SF3D 在视觉效果上明显优于其他方法, 并且在数值指标上也有显著提升.
在速度方面, 确实如作者所说, SF3D 的 UV 展开非常快, 只需 0.5s, 远快于其他方法的 10-30s.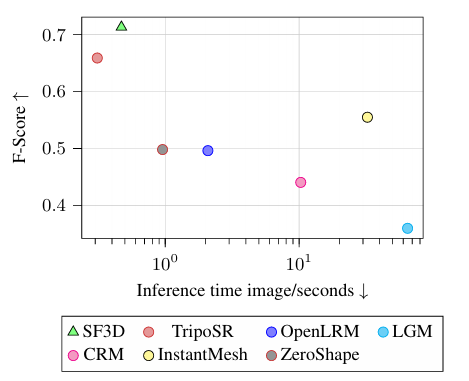
Conclusion
因此, 我似乎大致总结完了 SF3D 的主要结构, 从一张图像生成高质量的 mesh, 能不能对视频进行这样的操作呢? 我们看到这个任务里实际上用了大量生成的先验知识, 我在想一个完全
基于 image 的 3D reconstruction 方法, 能不能做到不依赖于这些先验知识?