引言 Transformer 在Attention is All You Need 一文中被提出, 本来想读一下原文的, 但是时间并不太够, 因此我们这里就简单捋一下就行.
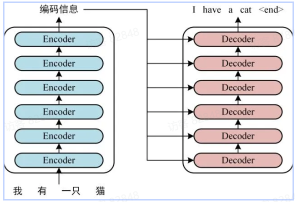
整体结构 Transformer 的整体结构如下图所示:
Transformer 的工作流程:
首先获取输入每一个词的表示向量X X
然后将X Z
Z X n × d n d
接着将目标序列的输入Y Z Y ^
使用的过程中, 翻译到单词i + 1 Mask 操作掩盖住未来的信息, 以防止模型在预测时看到未来的词.
OK, 下面我们来具体看看 Encoder Layer 和 Decoder Layer 的结构.
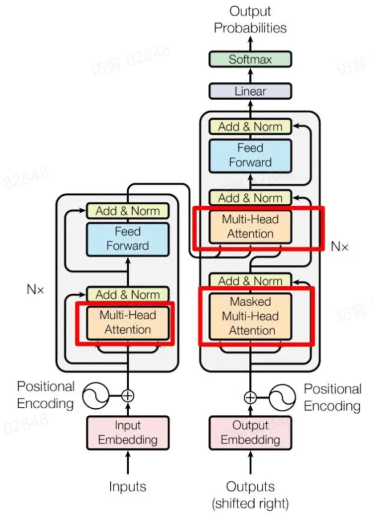
Self-Attention 机制 Transformer 的核心是 Self-Attention 机制, 其结构如下图所示:
左侧为Encoder block
右侧为Decoder block
红圈中的部分为Multi-Head Attention 机制, 是由多个 Self-Attention 组成的.
可以看到Encoder block 包含一个Multi-Head Attention 层.
Decoder block 包含两个Multi-Head Attention 层, 第一个用于处理目标序列的输入, 第二个用于结合 Encoder 的输出.每个 Attention 层后面都跟着一个**Feed-Forward Neural Network (FFN)**层.
因为Self-Attention 机制是 Transformer 的核心, 因此我们重点来看一下它的计算过程.
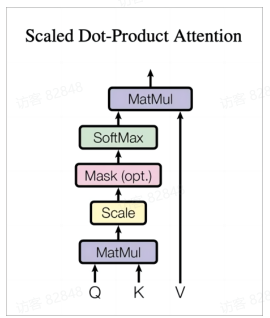
上图是Self-Attention 的计算流程图, 计算时需要用到三个矩阵: Query (Q K V X
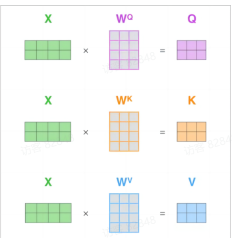
Q, K, V 的计算 Self-Attention 机制中, 对于输入的表示X ∈ R n × d W Q , W K , W V ∈ R d × d k Q , K , V Q = X W Q , K = X W K , V = X W V
实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 from math import sqrtclass SelfAttention (nn. Module): def __init__ (self, d_model, d_k, d_v ): " " " input: X: (batch_size, n, d_model) q: (batch_size, n, d_k) k: (batch_size, n, d_k) v: (batch_size, n, d_v) " " " super (SelfAttention, self ).__init__() self .d_k = d_k self .W_Q = nn. Linear(d_model, d_k) self .W_K = nn. Linear(d_model, d_k) self .W_V = nn. Linear(d_model, d_v) self ._norm_factor = sqrt(d_k) def forward (self, X ): Q = self .W_Q(X) K = self .W_K(X) V = self .W_V(X) scores = torch.matmul(Q, K.transpose(-2 , -1 )) / sqrt(self .d_k) attn_weights = torch.softmax(scores, dim=-1 ) output = torch.matmul(attn_weights, V) return output
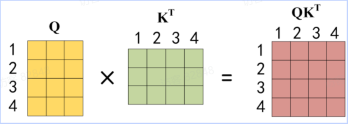
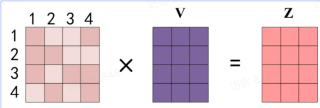
因此, 当我们得到了Q , K , V Attention ( Q , K , V ) = softmax ( d k Q K T ) V
得到Q K T
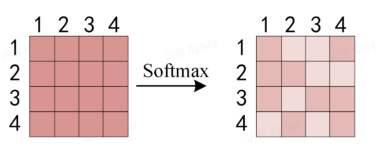
最后将归一化后的权重矩阵与V
上图中softmax 矩阵的第一行可以理解为单词 1 对其他单词的关注程度, 最终单词 1 的输出Z 1 V
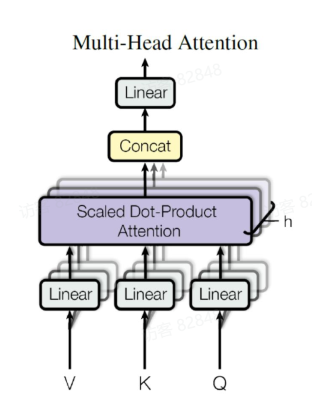
Multi-Head Attention 上一步中, 我们已经知道怎么使用 Self-Attention 机制来计算 Attention 的输出了, 但是 Transformer 中使用的是Multi-Head Attention 机制, 其结构如下图所示:
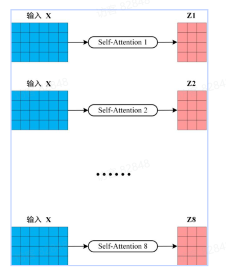
从上图中可以看到Multi-Head Attention 机制包含多个并行的 Self-Attention 头, 每个头都有自己的一组线性变换矩阵W Q i , W K i , W V i
首先将输入X
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 from math import sqrtclass MultiHeadAttention (nn. Module): def __init__ (self, d_model, d_k, d_v, h ): " " " input: X: (batch_size, n, d_model) q: (batch_size, d_model, d_k) k: (batch_size, d_model, d_k) v: (batch_size, d_model, d_v) " " " super (MultiHeadAttention, self ).__init__() self .h = h self .d_k = d_k self .d_v = d_v self .W_Q = nn. ModuleList([nn. Linear(d_model, d_k) for _ in range (h)]) self .W_K = nn. ModuleList([nn. Linear(d_model, d_k) for _ in range (h)]) self .W_V = nn. ModuleList([nn. Linear(d_model, d_v) for _ in range (h)]) self .linear = nn. Linear(h * d_v, d_model) def forward (self, X ): heads = [] for i in range (self .h): Q = self .W_Q[i](X) K = self .W_K[i](X) V = self .W_V[i](X) scores = torch.matmul(Q, K.transpose(-2 , -1 )) / sqrt(self .d_k) attn_weights = torch.softmax(scores, dim=-1 ) head = torch.matmul(attn_weights, V) heads.append(head) concat_heads = torch.cat(heads, dim=-1 ) output = self .linear(concat_heads) return output
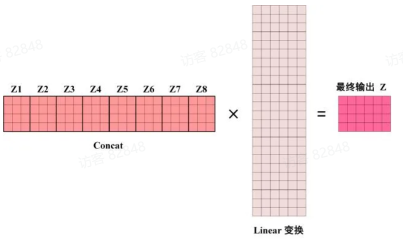
得到 8 个输出后, 将它们在最后一个维度上进行拼接, 得到一个新的表示, 然后通过一个线性变换矩阵W O d m o d e l
可见Multi-Head Attention 输出的矩阵维度与输入矩阵的维度相同, 这样就可以方便地将其与后续的层进行连接.
Other components 剩余的层比较简单, 因此不再赘述.
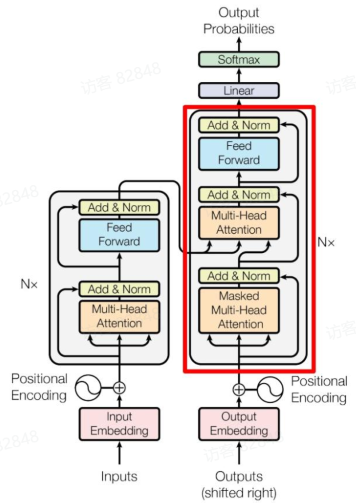
Decoder Layer Decoder Layer 的结构如下图红框内所示:
其与 Encoder Layer 的主要区别在于多了一个Masked Multi-Head Attention 层, 该层用于处理目标序列的输入, 并且在计算 Attention 时会掩盖住未来的信息, 以防止模型在预测时看到未来的词.
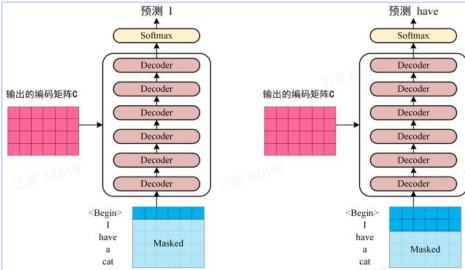
第一个Multi-Head Attention 我们重点解释一下 Mask 操作.
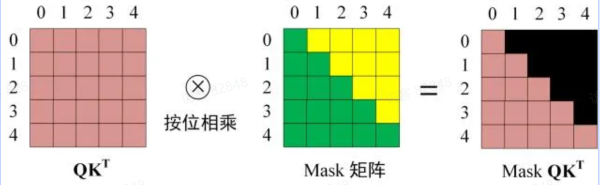
第一步是 Decoder 的输入矩阵和 Mask 矩阵, Mask 矩阵是一个上三角矩阵, 用于掩盖未来的信息.
接下来的操作和之前的 Self-Attention 机制类似, 通过输入矩阵计算Q , K , V Q K T
然后将 Mask 矩阵应用到Q K T
最后进行 Softmax 归一化, 并与V
第二个Multi-Head Attention 第二个 Multi-Head Attention 层与 Encoder Layer 中的 Multi-Head Attention 层类似, 只是这里的K V Z Q
根据 Encoder 的输出C K V D Q
时间复杂度分析 Transformer 的时间复杂度主要来自于 Self-Attention 机制. 对于一个长度为n O ( n 2 ⋅ d ) d Q K T n × n d L O ( L ⋅ n 2 ⋅ d )
总结 Transformer 应该是这样的.