SLAM Former 阅读
引言
最近几天读了SLAM-Former: Putting SLAM into One Transformer这篇很近很近的工作,本文笔记记录用于后续翻阅学习
首先, SLAM-Former 与之前读到的所有论文相似,都是致力于从 RGB 图像序列中恢复三维场景结构和相机位姿等属性的工作。但是与之前的工作(包含一个冗长复杂的 pipeline )不同,
SLAM-Former 对已有的 transformer 架构进行了大胆的改进,使之更适合进行重建任务,并在实验中得到了 competitive 的结果。
模型结构
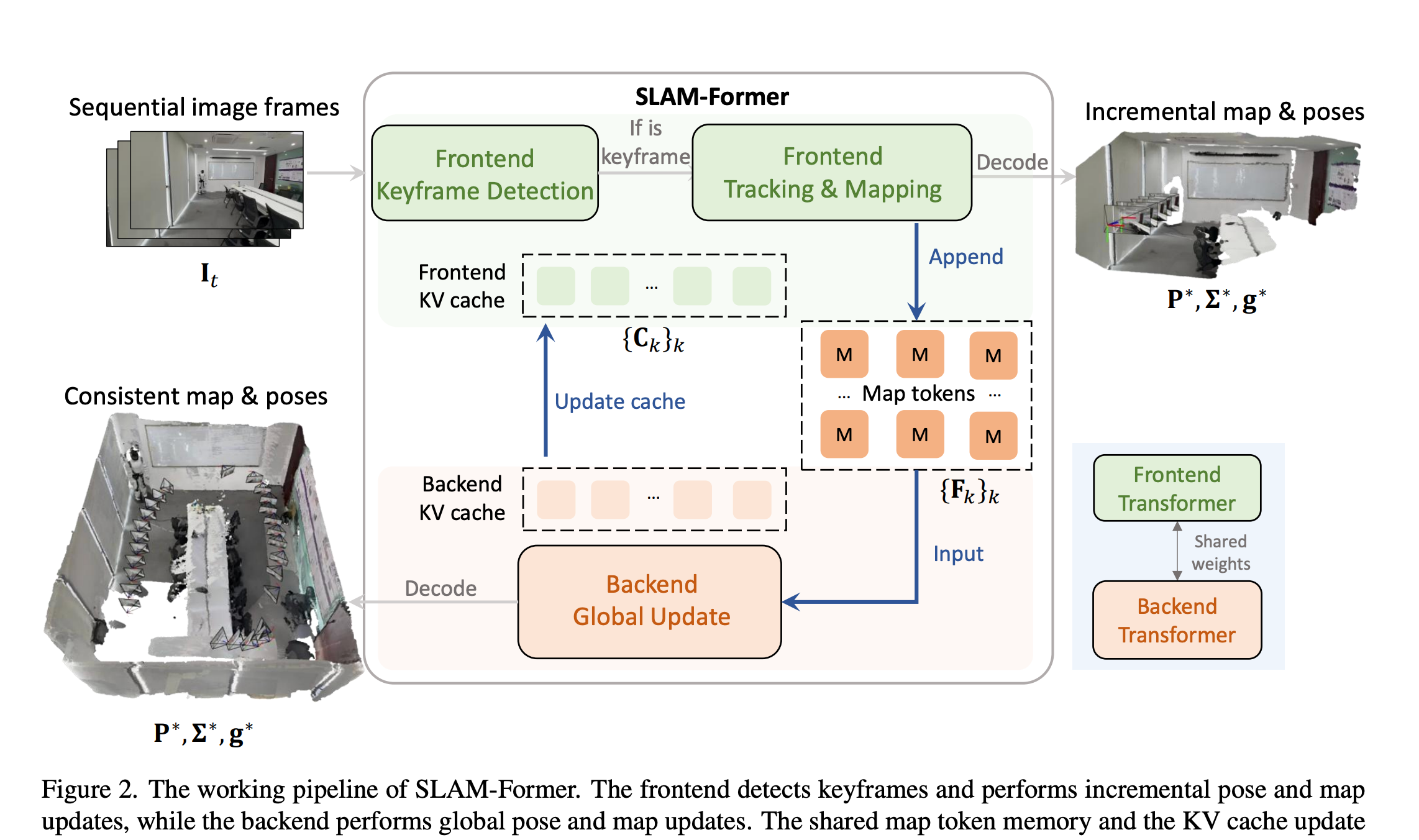
据作者所述, SLAM-Former 的主要 pipeline 由 frontend 和 backend 两部分组成,至于模型的 backbone , SLAM-Former 建立在一个 Transformer 架构之上,
而这个 Transformer aggregate 了 intraframe 和 interframe 的信息,并使用 task specific heads 预测不同的三维属性。
值得注意的是, 这个 Transformer 的输入与类似,对所有的输入的 image token 共享一个相同的 register tokens
从而使模型不依赖于一个不稳定的 reference frame 。
模型的 backbone 包含了层组合了 intra-frame attention 和 inter-frame attention
来联合捕捉图像内容和图像之间的关系。
此外, Front end 部分负责增量式的逐帧重建, back end 负责全局的点云对齐和相机优化,他们共享一个
Transformer backbone 。
Front end
图中大部分内容都是 front end 的处理细节,当一个新的 frame 输入时, frontend 首先会
决定其是否为 keyframe ,如果是的话,则会进行进一步处理。
当给定一个 frame sequence 时, frontend 将每一个 frame 映射到一个 map token 集合中:
这里, ${C_k}{K\in S}$表示之前 keyframe 的KV cache,
, 代表着 keyframe 的索引集合,是当前 frame 的 map token, 作为该 frame 的
一个隐式神经表示。 同时新的 KV cache 也通过$C_t = Cache(f(\mathbb{F}t))$产生,
也会视情况被扩充到${C_k}{K\in S}$中。
Keyframe detection
在上一步中我们已经对当前帧 generated 了 map token ,接下来我们需要决定是否为 keyframe.
作者采用了 pose head 来预测当前帧的 pose :
当当前 frame 的 relative pose 与最近的 keyframe 的 pose 之间的差异大于一个阈值时,
则将当前 frame 标记为 keyframe 。
但是作者在论文里又表明,在检测 frame 是否为 keyframe 时,他们并没有依赖 KV cache
, 而是直接应用了来检测,就相当于之前的 KV cache 是将该图片
与所有的 keyframe 进行 attention 计算,而这里则是只与最近的 keyframe 进行 attention 计算。
这样增加了效率并且避免了选取一个特定的 reference frame 。(这里似乎我没怎么懂跟特定的 reference frame 有什么关系)
Front end tracking and mapping
接着上一步,如果一个新的 frame 已经被认为是一个 keyframe ,我们就可以重新利用全部的 KV cache 来重新
计算他的 map token, 并更新 M, S.
好了, front end 到这里差不多结束了,作者说 frontend 只依赖于过去的 keyframe ,
使得其适合于 online 的 tracking ,然而, 这种处理顺序会导致误差累积和局部不一致,
为了解决这一问题,作者引入了一个 back end 模块来进行 global refinement.
Backend
Backend 的主要任务是 refine 所有的 frame 来达到全局的一致性。传统的
SLAM 系统通常会使用 loop closure 和 bundle adjustment 来实现这一点,
但是这些方法都非常的 costly, 作为对比,作者使用了一个 transformer-based 的
back end 来进行全局的优化。
作者认为这个设计的有效性在于 backend transformer 内部的 full attention 机制,
他的全局感受野使得模型能够完成误差纠正和结构一致性。
此外, 为了继承 backend refinement 的优势, frontend 和 backend 共享了 KV cache ,
使得 frontend 能够受益于 backend 的全局优化。
Training Strategy
与以往的一些论文不同, SLAM-Former 的创新点不止在于模型架构,也在于一些训练策略。
作者的目标是使一个 transformer 同时胜任 frontend 和 backend 的任务,为了达到这个目标,
作者用三种模式联合训练,每一个模式都对应着不同的输入输出对。
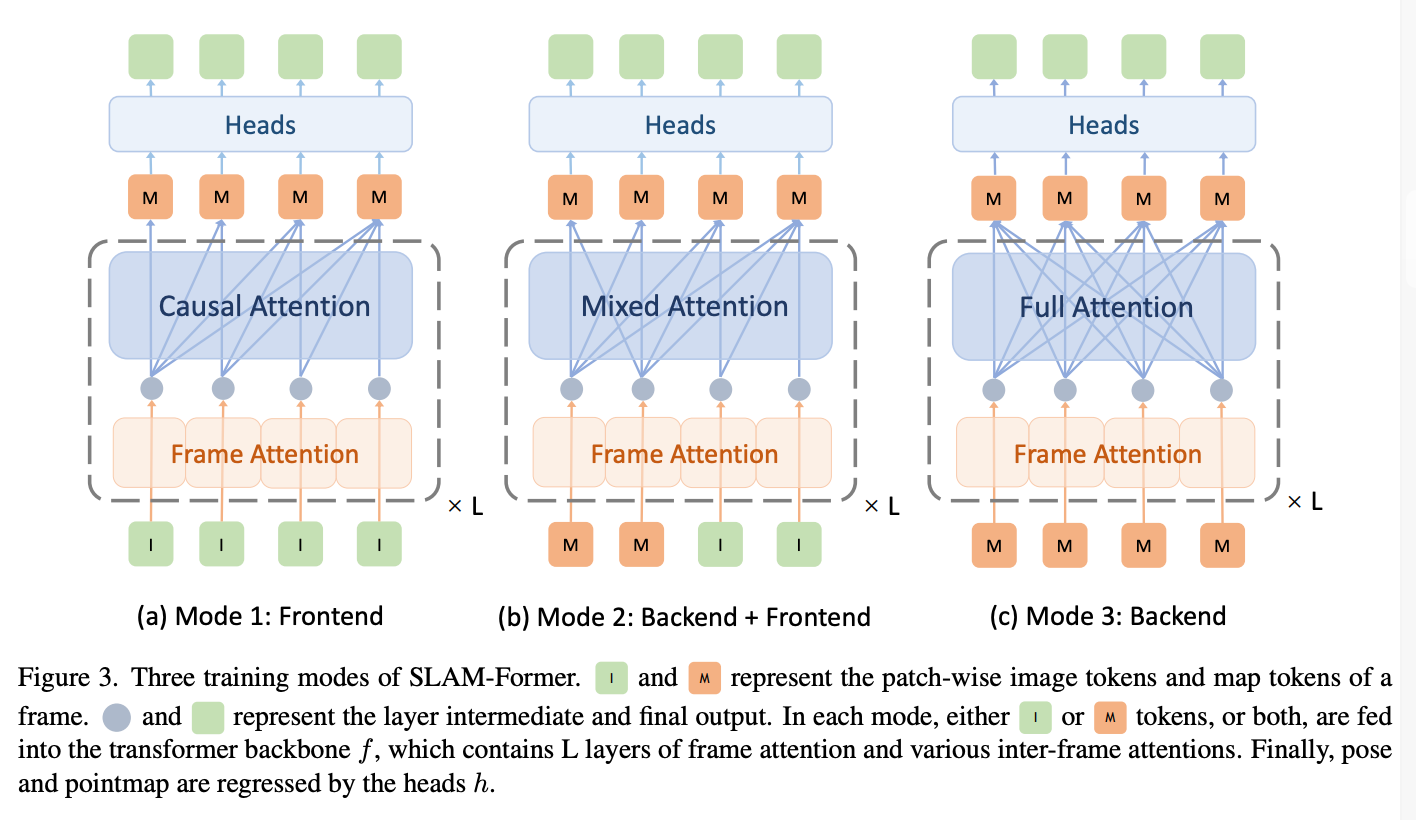
Training Frontend
Frontend 用了一个 causal mask 来确保每一个 frame 只能访问之前的 keyframe 。
然而,纯净的使用 causal mask 会自动的将第一帧作为 reference frame ,
作者又注意到党对两帧或更多帧进行联合操作时,没有单一的 refernce frame,
这避免了后续帧需要与 reference frame pose 相似的要求。
因此, 作者对前两帧使用了 full attention ,并同时对所有后续 frame 使用 causal mask,
在这种情况下, inference 时, keyframe detection 将最后一帧关键帧和当前的输入帧进行处理,
tracking and mapping 时, 前两个 keyframe 则会联合处理决定全局坐标。
作者的原文是:
For tracking and mapping, the
first two keyframes are jointly processed to determine the
global coordinate.
取前两帧的做法与之前的 tracking and mapping 部分提到的 use full KV cache 不符,
我感觉不怎么理解。
Training Frontend with Backend Cooperation
为了在 frontend 和 backend 之间建立联系,作者使用 maxed attention 来模拟 backend 和
cache sharing 的过程。
具体来说,采用混合注意力在一个统一的正向传播中同时完成地图精炼(后端/全注意力)和新数据处理,
并且前端的 casual attention 并非独立工作,而是以 KV cache 为条件,实现了高效且信息流一致的前端-后端协作,确保前端的实时处理结果能够立即对齐到后端修正后的全局结构。
woc 这什么花式操作啊
Training Backend
作者最后使用 full attention 来训练 backend transformer ,
Joint Training
在所有的三种模式中,三维属性均是由 task specific heads 预测的:
但值得注意的是, 并不像其他的工作一样, SLAM-Former 只预测每一帧的 local
pointmap 来避免设定一个特定的世界坐标系的需求,这倒是与非常相似。
剩下的 loss 函数都比较常规。
这三种模式都会在一个 batch 中共享权重依次训练。
Pipeline
在图片和叙述过程中, pipeline 已经是显而易见的,于是我便不再赘述。
Experimental Setup
本模型有 36 层 framewise 和 global attention 相结合的 transformer layer, 训了 10 个
epoch, 在 32 个 A100 上训练了 11 小时。可以可以。
Results
模型在 pose , tracking 和 reconstruction 等任务上都达到了很好的指标。数据冗长不再多说。
值得一提的是作者对 Front end 和 back end 的联系的理解。
back end assist front end 无疑是显而易见的,但是作者还发现 back end 同样也
benefit from front end, 作者解释了是因为 back end 使用了来自于 frontend 的
implicit 的顺序信息,从而使得 back end 能够更好地理解 frame 之间的关系。(迷)
总结
总之, SLAM-Former 通过对 transformer 架构的改进和训练策略的设计,
成功地实现了一个统一的模型来处理 SLAM 任务。
但 SLAM-Former 仍然存在一些局限性,比如说作者用 full attention 来替代传统的 loop
closure 和 bundle adjustment ,受限于 full attention 的计算复杂度,模型难以处理非常长的序列,
其次, frontend 不支持一个 local 的 inference , 因为在 inference 之前需要将所有的 KV cache 输入到 frontend 中。
此外, 文章中没有提到的是,我去看他们的 demo , 发现重建结果有很明显的分块化现象,目前不知是否与 transformer 的架构有关。
此文撰写的时候, SLAM-Former 的代码尚未开源,期待后续的代码发布。
SLAM Former 阅读