# Pre-save the RGB images along with their corresponding masks # in preparation for visualization at last. rgb_imgs = [] for i inrange(len(data_views)): if data_views[i][' img' ].shape[0] == 1: data_views[i][' img' ] = data_views[i][' img' ][0] rgb_imgs.append(transform_img(dict(img=data_views[i][' img' ][None]))[..., : :-1]) if' valid_mask' notin data_views[0]: valid_masks = None else: valid_masks = [view[' valid_mask' ] for view in data_views]
#preprocess data for extracting their img tokens with encoder for view in data_views: view[' img' ] = torch.tensor(view[' img' ][None]) view[' true_shape' ] = torch.tensor(view[' true_shape' ][None]) for key in [' valid_mask' , ' pts3d_cam' , ' pts3d' ]: if key in view: del view[key] to_device(view, device=args.device) # pre-extract img tokens by encoder, which can be reused # in the following inference by both i2p and l2w models res_shapes, res_feats, res_poses = get_img_tokens(data_views, i2p_model) # 300+fps print(' finish pre-extracting img tokens' )
# decide the stride of sampling keyframes, as well as other related parameters if args.keyframe_stride == -1: kf_stride = adapt_keyframe_stride(input_views, i2p_model, win_r = 3, adapt_min=args.keyframe_adapt_min, adapt_max=args.keyframe_adapt_max, adapt_stride=args.keyframe_adapt_stride) else: kf_stride = args.keyframe_stride
# start reconstrution of the whole scene init_num = len(initial_pcds) per_frame_res = dict(i2p_pcds=[], i2p_confs=[], l2w_pcds=[], l2w_confs=[]) for key in per_frame_res: per_frame_res[key] = [Nonefor _ inrange(num_views)]
registered_confs_mean = [_ for _ inrange(num_views)]
# set up the world coordinates with the initial window for i inrange(init_num): per_frame_res[' l2w_confs' ][i*kf_stride] = initial_confs[i][0].to(args.device) # 224,224 registered_confs_mean[i*kf_stride] = per_frame_res[' l2w_confs' ][i*kf_stride].mean().cpu()
# initialize the buffering set with the initial window assert args.buffer_size < = 0or args.buffer_size > = init_num buffering_set_ids = [i*kf_stride for i inrange(init_num)]
# set up the world coordinates with frames in the initial window for i inrange(init_num): input_views[i*kf_stride][' pts3d_world' ] = initial_pcds[i] initial_valid_masks = [conf > conf_thres_i2p for conf in initial_confs] # 1,224,224 normed_pts = normalize_views([view[' pts3d_world' ] for view in input_views[: init_num*kf_stride: kf_stride]], initial_valid_masks) for i inrange(init_num): input_views[i*kf_stride][' pts3d_world' ] = normed_pts[i] # filter out points with low confidence input_views[i*kf_stride][' pts3d_world' ][~initial_valid_masks[i]] = 0 per_frame_res[' l2w_pcds' ][i*kf_stride] = normed_pts[i] # 224,224,3
for view_id in tqdm(range(num_views), desc=" I2P resonstruction" ): # skip the views in the initial window if view_id in buffering_set_ids: # trick to mark the keyframe in the initial window if view_id // kf_stride == init_ref_id: per_frame_res[' i2p_pcds' ][view_id] = per_frame_res[' l2w_pcds' ][view_id].cpu() else: per_frame_res[' i2p_pcds' ][view_id] = torch.zeros_like(per_frame_res[' l2w_pcds' ][view_id], device=" cpu" ) per_frame_res[' i2p_confs' ][view_id] = per_frame_res[' l2w_confs' ][view_id].cpu() continue # construct the local window sel_ids = [view_id] for i inrange(1, win_r+1): if view_id-i*adj_distance > = 0: sel_ids.append(view_id-i*adj_distance) if view_id+i*adj_distance < num_views: sel_ids.append(view_id+i*adj_distance) local_views = [input_views[id] foridin sel_ids] ref_id = 0 # recover points in the local window, and save the keyframe points and confs output = i2p_inference_batch([local_views], i2p_model, ref_id=ref_id, tocpu=False, unsqueeze=False)[' preds' ] #save results of the i2p model per_frame_res[' i2p_pcds' ][view_id] = output[ref_id][' pts3d' ].cpu() # 1,224,224,3 per_frame_res[' i2p_confs' ][view_id] = output[ref_id][' conf' ][0].cpu() # 224,224
# Special treatment: register the frames within the range of initial window with L2W model # TODO: batchify if kf_stride > 1: max_conf_mean = -1 for view_id in tqdm(range((init_num-1)*kf_stride), desc=" pre-registering" ): if view_id % kf_stride == 0: continue # construct the input for L2W model l2w_input_views = [input_views[view_id]] + [input_views[id] foridin buffering_set_ids] # (for defination of ref_ids, see the doc of l2w_model) output = l2w_inference(l2w_input_views, l2w_model, ref_ids=list(range(1, len(l2w_input_views))), device=args.device, normalize=args.norm_input) # process the output of L2W model input_views[view_id][' pts3d_world' ] = output[0][' pts3d_in_other_view' ] # 1,224,224,3 conf_map = output[0][' conf' ] # 1,224,224 per_frame_res[' l2w_confs' ][view_id] = conf_map[0] # 224,224 registered_confs_mean[view_id] = conf_map.mean().cpu() per_frame_res[' l2w_pcds' ][view_id] = input_views[view_id][' pts3d_world' ] if registered_confs_mean[view_id] > max_conf_mean: max_conf_mean = registered_confs_mean[view_id] print(f' finish aligning { (init_num-1)*kf_stride} head frames, with a max mean confidence of { max_conf_mean: .2f} ' )
# A problem is that the registered_confs_mean of the initial window is generated by I2P model, # while the registered_confs_mean of the frames within the initial window is generated by L2W model, # so there exists a gap. Here we try to align it. max_initial_conf_mean = -1 for i inrange(init_num): if registered_confs_mean[i*kf_stride] > max_initial_conf_mean: max_initial_conf_mean = registered_confs_mean[i*kf_stride] factor = max_conf_mean/max_initial_conf_mean # print(f' align register confidence with a factor { factor} ' ) for i inrange(init_num): per_frame_res[' l2w_confs' ][i*kf_stride] *= factor registered_confs_mean[i*kf_stride] = per_frame_res[' l2w_confs' ][i*kf_stride].mean().cpu()
对剩下的views进行注册
OK ,经过了以上的对于初始帧的特殊处理,我们终于踏入了正途:在过程中对每个帧进行实时处理
从buffer set里选择最相近的sel_num个帧:
1 2 3 4 5 6 7 8
# select sccene frames in the buffering set to work as a global reference cand_ref_ids = buffering_set_ids ref_views, sel_pool_ids = scene_frame_retrieve( [input_views[i] for i in cand_ref_ids], input_views[ni: ni+num_register: 2], i2p_model, sel_num=num_scene_frame, # cand_recon_confs=[per_frame_res[' l2w_confs' ][i] for i in cand_ref_ids], depth=2)
# register the source frames in the local coordinates to the world coordinates with L2W model l2w_input_views = ref_views + input_views[ni: max_id+1] input_view_num = len(ref_views) + max_id - ni + 1 assert input_view_num == len(l2w_input_views)
# process the output of L2W model src_ids_local = [id+len(ref_views) foridinrange(max_id-ni+1)] # the ids of src views in the local window src_ids_global = [idforidinrange(ni, max_id+1)] #the ids of src views in the whole dataset succ_num = 0 foridinrange(len(src_ids_global)): output_id = src_ids_local[id] # the id of the output in the output list view_id = src_ids_global[id] # the id of the view in all views conf_map = output[output_id][' conf' ] # 1,224,224 input_views[view_id][' pts3d_world' ] = output[output_id][' pts3d_in_other_view' ] # 1,224,224,3 per_frame_res[' l2w_confs' ][view_id] = conf_map[0] registered_confs_mean[view_id] = conf_map[0].mean().cpu() per_frame_res[' l2w_pcds' ][view_id] = input_views[view_id][' pts3d_world' ] succ_num += 1
# update the buffering set if next_register_id - milestone > = update_buffer_intv: while(next_register_id - milestone > = kf_stride): candi_frame_id += 1 full_flag = max_buffer_size > 0andlen(buffering_set_ids) > = max_buffer_size insert_flag = (not full_flag) or ((strategy == ' fifo' ) or (strategy == ' reservoir' and np.random.rand() < max_buffer_size/candi_frame_id)) ifnot insert_flag: milestone += kf_stride continue # Use offest to ensure the selected view is not too close to the last selected view # If the last selected view is 0, # the next selected view should be at least kf_stride*3//4 frames away start_ids_offset = max(0, buffering_set_ids[-1]+kf_stride*3//4 - milestone) # get the mean confidence of the candidate views mean_cand_recon_confs = torch.stack([registered_confs_mean[i] for i inrange(milestone+start_ids_offset, milestone+kf_stride)]) mean_cand_local_confs = torch.stack([local_confs_mean[i] for i inrange(milestone+start_ids_offset, milestone+kf_stride)]) # normalize the confidence to [0,1], to avoid overconfidence mean_cand_recon_confs = (mean_cand_recon_confs - 1)/mean_cand_recon_confs # transform to sigmoid mean_cand_local_confs = (mean_cand_local_confs - 1)/mean_cand_local_confs # the final confidence is the product of the two kinds of confidences mean_cand_confs = mean_cand_recon_confs*mean_cand_local_confs most_conf_id = mean_cand_confs.argmax().item() most_conf_id += start_ids_offset id_to_buffer = milestone + most_conf_id buffering_set_ids.append(id_to_buffer) # print(f" add ref view { id_to_buffer} " ) # since we have inserted a new frame, overflow must happen when full_flag is True if full_flag: if strategy == ' reservoir' : buffering_set_ids.pop(np.random.randint(max_buffer_size)) elif strategy == ' fifo' : buffering_set_ids.pop(0) # print(next_register_id, buffering_set_ids) milestone += kf_stride # transfer the data to cpu if it is not in the buffering set, to save gpu memory for i inrange(next_register_id): to_device(input_views[i], device=args.device if i in buffering_set_ids else' cpu' )
if is_have_mask_rgb: valid_masks.append(data_views[i][' valid_mask' ])
# process now image for extracting its img token with encoder data_views[i][' img' ] = torch.tensor(data_views[i][' img' ][None]) data_views[i][' true_shape' ] = torch.tensor(data_views[i][' true_shape' ][None]) for key in [' valid_mask' , ' pts3d_cam' , ' pts3d' ]: if key in data_views[i]: del data_views[key] to_device(data_views[i], device=args.device)
# pre-extract img tokens by encoder, which can be reused # in the following inference by both i2p and l2w models temp_shape, temp_feat, temp_pose = get_single_img_tokens([data_views[i]], i2p_model, True) res_shapes.append(temp_shape[0]) res_feats.append(temp_feat[0]) res_poses.append(temp_pose[0]) print(f" finish pre-extracting img token of view { i} " )
input_views.append(dict(label=data_views[i][' label' ], img_tokens=temp_feat[0], true_shape=data_views[i][' true_shape' ], img_pos=temp_pose[0])) for key in per_frame_res: per_frame_res[key].append(None) registered_confs_mean.append(i)
# accumulate the initial window frames if i < (initial_winsize - 1)*kf_stride and i % kf_stride == 0: continue elif i == (initial_winsize - 1)*kf_stride: initial_pcds, initial_confs, init_ref_id = initialize_scene(input_views[: initial_winsize*kf_stride: kf_stride], i2p_model, winsize=initial_winsize, return_ref_id=True) # set up the world coordinates with the initial window init_num = len(initial_pcds) for j inrange(init_num): per_frame_res[' l2w_confs' ][j * kf_stride] = initial_confs[j][0].to(args.device) registered_confs_mean[j * kf_stride] = per_frame_res[' l2w_confs' ][j * kf_stride].mean().cpu() # initialize the buffering set with the initial window assert args.buffer_size < = 0or args.buffer_size > = init_num buffering_set_ids = [j*kf_stride for j inrange(init_num)] # set ip the woeld coordinates with frames in the initial window for j inrange(init_num): input_views[j*kf_stride][' pts3d_world' ] = initial_pcds[j] initial_valid_masks = [conf > conf_thres_i2p for conf in initial_confs] normed_pts = normalize_views([view[' pts3d_world' ] for view in input_views[: init_num*kf_stride: kf_stride]], initial_valid_masks) for j inrange(init_num): input_views[j*kf_stride][' pts3d_world' ] = normed_pts[j] # filter out points with low confidence input_views[j*kf_stride][' pts3d_world' ][~initial_valid_masks[j]] = 0 per_frame_res[' l2w_pcds' ][j*kf_stride] = normed_pts[j]
elif i < (initial_winsize - 1) * kf_stride: continue
# first recover the accumulate views if i == (initial_winsize - 1) * kf_stride: for view_id inrange(i + 1): # skip the views in the initial window if view_id in buffering_set_ids: # trick to mark the keyframe in the initial window if view_id // kf_stride == init_ref_id: per_frame_res[' i2p_pcds' ][view_id] = per_frame_res[' l2w_pcds' ][view_id].cpu() else: per_frame_res[' i2p_pcds' ][view_id] = torch.zeros_like(per_frame_res[' l2w_pcds' ][view_id], device=" cpu" ) per_frame_res[' i2p_confs' ][view_id] = per_frame_res[' l2w_confs' ][view_id].cpu() print(f" finish revocer pcd of frame { view_id} in their local coordinates(in buffer set), with a mean confidence of { per_frame_res[' i2p_confs' ][view_id].mean(): .2f} up to now." ) continue # construct the local window with the initial views sel_ids = [view_id] for j inrange(1, win_r + 1): if view_id - j * adj_distance > = 0: sel_ids.append(view_id - j * adj_distance) if view_id + j * adj_distance < i: sel_ids.append(view_id + j * adj_distance) local_views = [input_views[id] foridin sel_ids] ref_id = 0
# recover poionts in the initial window, and save the keyframe points and confs output = i2p_inference_batch([local_views], i2p_model, ref_id=ref_id, tocpu=False, unsqueeze=False)[' preds' ] # save results of the i2p model for the initial window per_frame_res[' i2p_pcds' ][view_id] = output[ref_id][' pts3d' ].cpu() per_frame_res[' i2p_confs' ][view_id] = output[ref_id][' conf' ][0].cpu()
local_confs_mean_up2now = [conf.mean() for conf in per_frame_res[' i2p_confs' ] if conf isnotNone] print(f" finish revocer pcd of frame { view_id} in their local coordinates, with a mean confidence of { torch.stack(local_confs_mean_up2now).mean(): .2f} up to now." )
# Special treatment: register the frames within the range of initial window with L2W model if kf_stride > 1: max_conf_mean = -1 for view_id in tqdm(range((init_num - 1) * kf_stride), desc=" pre-registering" ): if view_id % kf_stride == 0: continue # construct the input for L2W model
l2w_input_views = [input_views[view_id]] + [input_views[id] foridin buffering_set_ids] # (for defination of ref_ids, seee the doc of l2w_model) output = l2w_inference(l2w_input_views, l2w_model, ref_ids=list(range(1, len(l2w_input_views))), device=args.device, normalize=args.norm_input) # process the output of L2W model input_views[view_id][' pts3d_world' ] = output[0][' pts3d_in_other_view' ] # 1,224,224,3 conf_map = output[0][' conf' ] # 1,224,224 per_frame_res[' l2w_confs' ][view_id] = conf_map[0] # 224,224 registered_confs_mean[view_id] = conf_map.mean().cpu() per_frame_res[' l2w_pcds' ][view_id] = input_views[view_id][' pts3d_world' ] if registered_confs_mean[view_id] > max_conf_mean: max_conf_mean = registered_confs_mean[view_id] print(f' finish aligning { (init_num)*kf_stride} head frames, with a max mean confidence of { max_conf_mean: .2f} ' ) # A problem is that the registered_confs_mean of the initial window is generated by I2P model, # while the registered_confs_mean of the frames within the initial window is generated by L2W model, # so there exists a gap. Here we try to align it. max_initial_conf_mean = -1 for i inrange(init_num): if registered_confs_mean[i*kf_stride] > max_initial_conf_mean: max_initial_conf_mean = registered_confs_mean[i*kf_stride] factor = max_conf_mean/max_initial_conf_mean # print(f' align register confidence with a factor { factor} ' ) for i inrange(init_num): per_frame_res[' l2w_confs' ][i*kf_stride] *= factor registered_confs_mean[i*kf_stride] = per_frame_res[' l2w_confs' ][i*kf_stride].mean().cpu() # register the rest frames with L2W model next_register_id = (init_num - 1) * kf_stride + 1 milestone = init_num * kf_stride + 1 update_buffer_intv = kf_stride*args.update_buffer_intv # update the buffering set every update_buffer_intv frames max_buffer_size = args.buffer_size strategy = args.buffer_strategy candi_frame_id = len(buffering_set_ids) # used for the reservoir sampling strategy continue
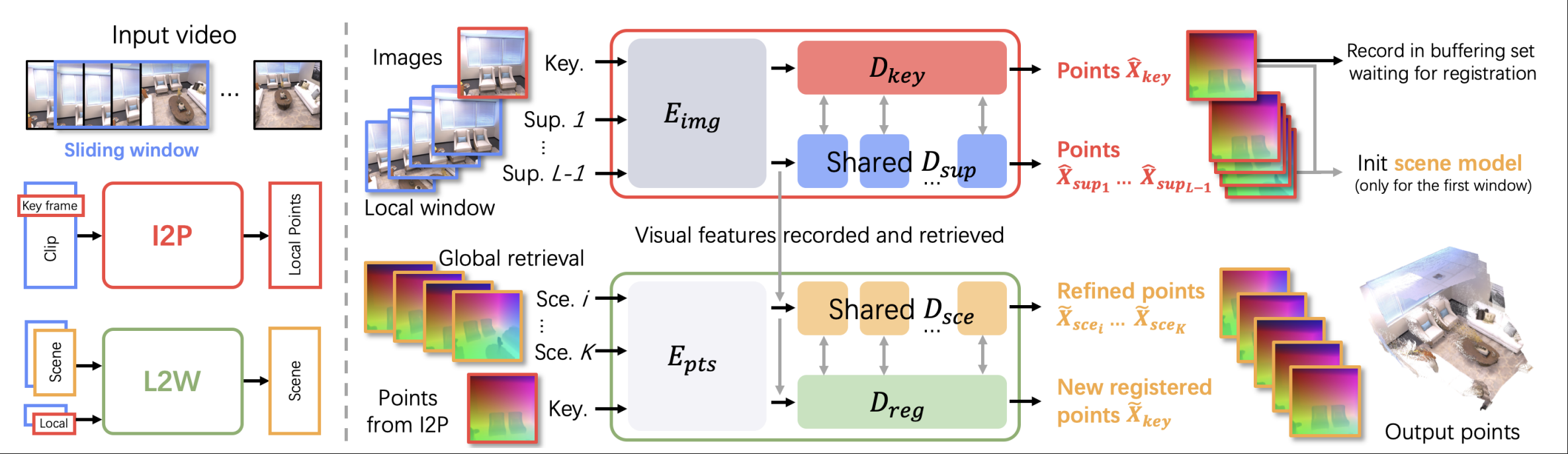
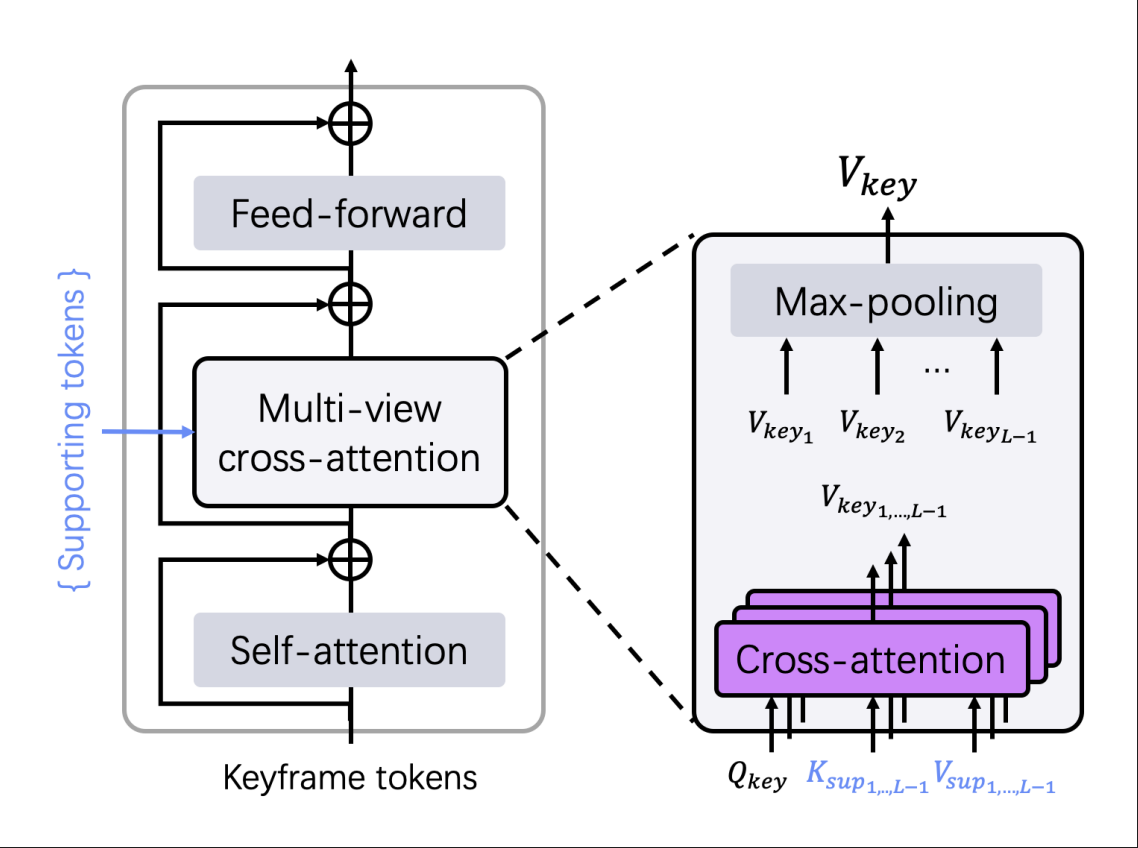
Scene Decoder 同样将所有 token 作为输入,但是它的目的是在不改变场景坐标系的情况下,精化坐标几何。他同样采用与Dkey相同的架构,但是他是对每一个在已选中的关键帧点图进行优化:G<em>scei=D</em>sce(F<em>scei,F</em>key),i=1,…,K 通过这样的方式将已生成的 point map 进行优化
Here, I build my first website(not the first but the first one I’m serious about building/running)😋.
My website will include:
Study course expriences
This kind of content will record my experiences learning some meaningful courses in PKU.I hope it will help me review my courses.
Research experiences
As a college student, researching and finding will be the main task in the future. Currently I am interested in 3R(3D reconstruction). So maybe I will update huge contents about my reflections for each paper.
My own projects
Of course, my some great(just in my standard) project will be post on the site. It’s meaningful to me as long as I think it’s great, regardless of how others see it.
…
Above might be the main topics of content in the site.
Additions
The posts will be in Chinese and English randomly(maybe most time Chinese🤣). Please forgive my poor English.