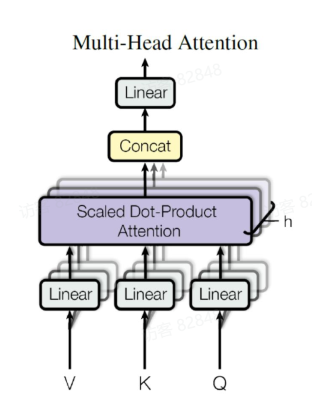
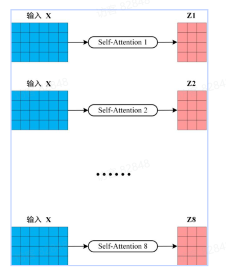
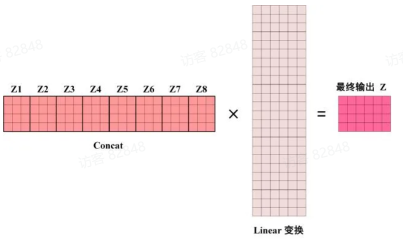
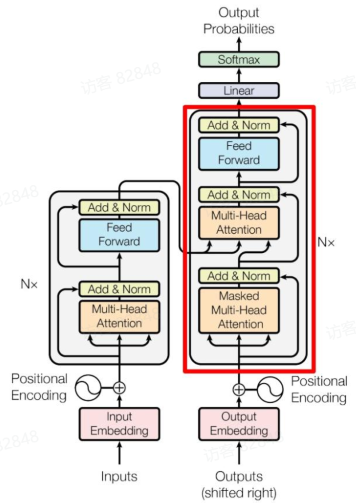
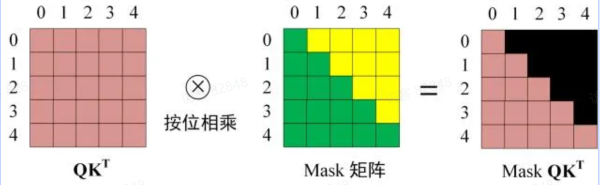
A 题
B 题
这里又来到了经典的小北问答环节,结合一些理论知识和具体论文的查阅,我们可以对题目进行详细的分析和解答。
1. Amdahl & Gustafson
某程序的代码中 10% 必须串行执行, 90% 可完美并行。
根据 Amdahl’s Law ,无论核心数如何增加,该程序的理论最大加速比极限是 ____ 倍;
若在 10 核系统中通过扩大问题规模来保持每核计算负载不变,根据 Gustafson’s Law ,该系统的加速比将达到 ____ 倍。
首先,根据 Amdahl 定律,加速比 S 可以通过以下公式计算:
其中 P 是可并行部分的比例, N 是处理器的数量。对于该问题, P = 0.9 ( 90% 可并行),串行部分为 0.1 ( 10% 必须串行)。当 N 趋近于无穷大时,公式简化为:
因此,该程序的理论最大加速比极限是 10 倍。
接下来,根据 Gustafson 定律,加速比 S 可以通过以下公式计算:
在 10 核系统中, N = 10 , P = 0.9 ,因此:
因此,在 10 核系统中通过扩大问题规模来保持每核计算负载不变,该系统的加速比将达到 9.1 倍。
2. OpenMP
以下代码使用 OpenMP 并行执行循环:
1 | int sum = 0; |
关于该代码,请问以下说法中正确的是 ____ 。
| 选项 | 描述 |
|---|---|
| A | 代码一定能正确计算出 0 到 99 的和( 4950 ) |
| B | 代码存在数据竞争, 结果不确定。 |
| C | sum变量默认为private,每个线程有自己的副本。 |
| D | OpenMP 会自动为sum变量添加原子操作,保证结果正确。 |
正确答案是 B 。
解释如下:
- 选项 A 是错误的,因为代码中存在数据竞争,多个线程同时修改共享变量
sum,导致结果不确定。 - 选项 B 是正确的,因为在并行执行时,多个线程可能同时读取和写入
sum,导致数据竞争,从而使得最终结果不确定。 - 选项 C 是错误的,因为
sum变量在默认情况下是共享的( shared ),而不是私有的( private )。因此,所有线程都访问同一个sum变量。 - 选项 D 是错误的,因为 OpenMP 不会自动为共享变量添加原子操作。要确保结果正确,需要显式地使用
#pragma omp atomic或其他同步机制来保护对sum的访问。
3. 低精度
已知 IEEE 754 标准的 FP32 拥有 8 位指数位。请问:
- BF16 拥有 ____ 位指数位,____ 位尾数位
- NVFP4 拥有 ____ 位指数位,____ 位尾数位
提示:可以查阅资料,了解 NVFP4 如何在低精度下保持较高的数值范围和动态范围。
NVFP4 比较特殊,他只有 4 个 bit ,显然如果直接使用的话,其范围会很小,精度也不理想,但经过查阅资料可知:
NVFP4 首先将一组数视为了一个块,一个块中会共享一个高精度的 scale factor ,确定大致的数量级,然后 NVFP4 只存储每个数相对于这个 scale factor 的偏移量,这样就能在保持较大数值范围的同时,使用更少的位数来表示每个数,从而提高了存储效率和计算速度。
4. MPI 通信
4.1 基本原语
4 个进程执行以下代码,每个进程有局部值 local_val ,操作后每个进程都有所有进程的值。
1 | int rank; |
4.2 通信器
创建一个 2 维笛卡尔拓扑,尺寸为 2×2 ,行优先排列,允许环绕连接。
1 | MPI_Comm comm_cart; |
4.1 基本原语
可以使用 MPI_Allgather 来实现该功能。代码如下:
1 | MPI_Allgather(& local_val, 1, MPI_INT, recv_buf, 1, MPI_INT, MPI_COMM_WORLD); |
这行代码会将每个进程的 local_val 收集到所有进程的 recv_buf 中。
4.2 通信器
可以使用 MPI_Cart_create 来创建一个二维笛卡尔拓扑。代码如下:
1 | MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, 1, & comm_cart); |
这行代码会创建一个 2x2 的笛卡尔拓扑通信器 comm_cart,并允许环绕连接。
5.NCCL 延迟
在深度学习的并行推理与训练中,进程之间会频繁进行集合通信操作。 NVIDIA 的开源集合通信库 NCCL ,提供了在 GPU 之间进行集合通信的高性能解决方案。
当在异构的硬件上进行大规模集合通信时,如何选择通信的算法将很影响集合通信操作的效率。为了解决这个问题, NCCL 的解决方案是:基于一套硬编码的调优常数,估算不同集合通信算法下的集合通信完成时间,由此选择最优的算法。
问题:在 NCCL 2.28 的默认调优常量中,用 NVLink 连接的两 GPU 、采用 Tree 算法和 LL 协议时,在估算时每跳(单步)的硬件延迟取值为 ______ µs 。
根据 NCCL 2.28 的默认调优常量,当使用 NVLink 连接的两 GPU ,采用 Tree 算法和 LL 协议时,每跳(单步)的硬件延迟取值为 0.6 µs 。
具体参考资料可见 NCCL Github src/graph/tunning.cc中的 151 行。
6. 高性能网络
Rail-optimized networking 与 Clos 都是高性能网络设计方案。以下说法正确的有:
| 选项 | 描述 |
|---|---|
| A | 在 Rail-optimized 网络中,来自不同 HB 域( High-Bandwidth Domain )但具有相同 local rank 的 GPU 会被连接到同一个 rail switch 上,以减少跨域通信的延迟 |
| B | 常见部署模式下, Rail-optimized 网络相比传统 Clos 网络的主要优势是完全不需要 Spine 层交换机,因此可以大大节省网络设备成本 |
| C | Clos 网络因其使用 Spanning Tree Protocol (STP) 而在大规模部署时存在扩展性问题,这是 Rail-optimized 网络要解决的核心问题之一 |
| D | Rail-optimized 网络保证了任何情况下集群内任意两个 GPU 之间都能以网络线速(如 400 Gbps InfiniBand )进行通信,无论它们是否在同一个 rail 中 |
| E | NCCL 2.12 引入的 PXN 特性可以结合 NVLink 和 PCI 通信来优化网络流量,这个优化对于 Rail-optimized 网络尤为重要 |
| F | 对于 LLM 训练工作负载,最优的通信策略会将大部分网络流量集中在相同 local rank 的 NIC 之间,并且会多用 NVLink 等高速互联进行跨 rail 交换,这使得 Rail-optimized 架构特别适合此类场景 |
正确答案是 A 、 E 、 F 。
解释如下:
选项 A 是正确的,这是 Rail-optimized 网络的核心定义。 在这种架构中,网络拓扑是根据 GPU 的 rank 进行物理隔离的。例如,所有服务器上的 0 号 GPU 都连接到同一组交换机( Rail 0 ), 1 号 GPU 连接到另一组( Rail 1 )。这使得在进行数据并行( Data Parallelism )训练时, AllReduce 等操作只需在同一个 Rail 内进行,无需跨越复杂的交换层级,大大降低了拥塞和延迟。
选项 B 是错误的, Rail-optimized 仍然基于 Clos 架构,通常需要 Spine 交换机。 Rail-optimized 描述的是 Leaf 层交换机与 GPU 的连接方式以及流量的导向方式,而不是一种去除了 Spine 的新型拓扑。对于大规模集群(超过一个 Leaf 交换机的容量), Rail 0 的 Leaf 交换机之间仍然需要通过 Spine 交换机互联,以构成一个完整的 Rail 0 网络平面。
选项 C 是错误的, Clos 网络并不使用 STP ,且 STP 是传统以太网的痛点。 传统二层以太网使用 STP (Spanning Tree Protocol) 防止环路,这会导致大量链路被阻塞,带宽利用率低。而现代 Data Center Clos 网络(无论是基于 IP 路由的 ECMP 还是 InfiniBand )的设计初衷就是利用所有链路进行负载均衡,完全摒弃了 STP 。因此, C 选项描述的前提本身就是错误的。
选项 D 是错误的, Rail-optimized 并不保证“跨 Rail”通信的效率等同于“同 Rail”。 Rail-optimized 的设计哲学是“专路专用”。虽然物理上可以通过 Spine 进行跨 Rail 通信(例如 Node A 的 GPU 0 发给 Node B 的 GPU 1 ),但这通常不是最优路径,且可能面临 oversubscription (收敛比)的问题。实际上,这种架构倾向于利用 E 选项和 F 选项提到的技术来避免在网络层面上进行跨 Rail 数据传输。
选项 E 是正确的, PXN (PCIe/NVLink Cross-NIC) 是解决 Rail 架构灵活性的关键。 在 Rail-optimized 网络中,如果 GPU 0 需要向网络中的 Rail 1 发送数据,传统的路径非常低效(走 PCIe -> CPU -> NIC -> Switch ->…)。 NCCL 的 PXN 特性允许 GPU 0 通过 NVLink 直接把数据传给同机的 GPU 1 ,然后由 GPU 1 的 NIC (连接着 Rail 1 )发送出去。这相当于在节点内部利用 NVLink 完成了“变轨”,从而充分利用 Rail 网络的优势。
选项 F 是正确的,这准确描述了 LLM 训练中的混合通信模式。 在 LLM 训练中,通常结合了数据并行( DP )和模型并行( TP/PP )。
+ TP (Tensor Parallelism) 流量极大,通常限制在单机内部,完全走 NVLink 。 + DP (Data Parallelism) 需要跨机同步梯度,流量发生在相同 rank 的 GPU 之间,这完美契合 Rail-optimized 的网络路径。 + 如果需要跨 rank 的操作(如 Pipeline Parallelism 的某些阶段或特定的 All-to-All ),结合 NVLink (节点内)+ Rail (节点间)是目前最优的策略。
7. GPU
NVIDIA 的 Hopper 架构引入了 TMA ( Tensor Memory Accelerator ) 以提升 GPU 内存访问效率。以下说法正确的有:
| 选项 | 描述 |
|---|---|
| A | 相比 cp.async , TMA 可以直接将数据从全局内存加载到共享内存,无需经过寄存器中转,从而能节省寄存器 |
| B | 在 cutlass 的异步流水线抽象中, Producer 调用 producer_acquire 获取空闲的 buffer stage ,完成数据加载后调用 producer_commit 通知 Consumer ; Consumer 则通过 consumer_wait 等待数据就绪,使用完毕后调用 consumer_release 释放 buffer |
| C | 在使用 TMA 进行数据传输时,所有参与的线程都需要执行相同的 TMA 指令, TMA 硬件会自动处理线程间的协调 |
| D | Cutlass Pipeline 使用多级缓冲( multi-stage buffering ),通过 PipelineState 追踪当前读写的 stage index 和 phase ,实现 Producer 和 Consumer 之间的流水线重叠 |
| E | TMA 的 multicast 功能允许一次 TMA 操作将同一块数据广播到 Cluster 内的多个 Thread Block 的共享内存中,减少了重复的全局内存访问 |
| F | TMA 描述符( TMA Descriptor )需要在 kernel 启动前在 host 端创建,描述符中包含了张量的形状、步长和 swizzle 模式等信息, kernel 执行时通过预取描述符( prefetch_tma_descriptor )来减少首次 TMA 操作的延迟 |
正确答案是 B D E F.
解释 :
- 选项 A 是错误的。 Ampere 架构引入的 cp.async 指令同样也是绕过寄存器( Register File ),直接将数据从全局内存( GMEM )搬运到共享内存( SMEM )。
- 选项 B 是正确的。这描述了 Cutlass 异步流水线中 Producer 和 Consumer 之间的交互方式,符合 Cutlass 的设计理念。
- 选项 C 是错误的。 TMA 操作允许线程组内的线程根据需要选择性地执行 TMA 指令,而不是所有线程都必须执行相同的指令。如果所有线程都执行,会导致重复发射多个拷贝操作(除非有特殊的掩码处理)。这一点与 Ampere 的 cp.async (通常每个线程负责一部分)不同。
- 选项 D 是正确的。 Cutlass Pipeline 确实使用多级缓冲,通过 PipelineState 来追踪当前读写的 stage index 和 phase ,从而实现 Producer 和 Consumer 之间的流水线重叠。
- 选项 E 是正确的。 TMA 的 multicast 功能允许一次 TMA 操作将同一块数据广播到 Cluster 内的多个 Thread Block 的共享内存中,减少了重复的全局内存访问。
- 选项 F 是正确的。 TMA 描述符需要在 kernel 启动前在 host 端创建,包含张量的形状、步长和 swizzle 模式等信息, kernel 执行时通过预取描述符来减少首次 TMA 操作的延迟。
8. LLM
对于参数如下的一个标准的 Transformer-Decoder 模型,所有的 all reduce 操作都使用 ring all reduce 。假设一共有 4 张卡。
模型参数
| 参数 | 值 |
|---|---|
| 层数 | 32 层 |
| 隐藏层维度 (h) | 4096 |
| FFN 结构 | 两层线性层,中间层维度为 4h |
| 序列长度 | 2048 |
| Batch Size | 32 |
| 优化器 | Adam + 混合精度训练 |
| 精度设置 | 参数和梯度使用 fp16 , Adam 优化器状态使用 fp32 (包括 momentum 、 variance 和 master weights ) |
问题
请计算在以下三种并行方式下,进行一个 batch 的前向传播和反向传播,每张卡需要的发送量(以 GB 为单位):
数据并行:每张卡上存放完整的模型,把 batch 均匀拆分到每张卡上,分别计算完成后对梯度进行 All-Reduce 操作
流水并行:按层拆分模型放到不同卡上,只需要前向传播的时候发送 activation ,反向传播的时候发送 gradient 。(计算通信量时只考虑中间的卡)
张量并行:对于 MHA 操作,按照 head 拆分到不同卡上。对于 FFN ,第一个线性层按照输出维度进行拆分,第二个线性层按照输入维度进行拆分
计算过程如下:
数据并行:
模型参数量:
梯度大小:
通信量:
流水并行:
每层激活大小:
通信量:
张量并行:
单次 All-Reduce 大小:
单次 Ring All-Reduce 通信量:
总通信量:
9. UB 互联
在高性能计算系统中,集合通信( Collective Communication )的性能主要受带宽( Bandwidth ) 与延迟( Latency ) 两个因素制约。
NVIDIA 通过 NVLink 与 NVSwitch 构建 GPU 间的高速 Scale-up 互联网络,而华为则提出了 Unified Bus ( UB )协议,作为面向 NPU 的统一互联与内存访问机制。 UB 协议基于华为自研的 UB Switch 交换芯片,并通过高带宽物理链路 HCCS ( High-Capacity Coherent System ) 进行连接。
传统 AI 集群通常以 8 卡服务器为基本单元进行 Scale-out 扩展,而华为在 CloudMatrix 384 ( CM384 ) 架构中,通过两级 UB Switch 组网,将 384 颗昇腾 910C NPU 构建为一个统一的超节点( SuperPod )。在该超节点范围内,所有 NPU 均处于同一个低延迟的轨道优化网络中,实现全对等 Scale-up 互联。
CM384 进一步将 UB 网络划分为 7 个相互独立的物理平面。每颗 NPU 的 7 个 HCCS 接口分别接入不同的交换平面,从而保证大规模并行通信过程中,数据流在物理路径上完全隔离、无链路冲突。
问题
在 CloudMatrix 384 的标准满配部署方案中,为了支撑 384 颗昇腾 910C NPU 实现无收敛、全对等的 Scale-up 互联,系统采用两级交换架构。在该超节点的物理拓扑中,分别使用了:
- ____ 个 Level 1 UB Switch
- ____ 个 Level 2 UB Switch
- 最终实现了理论上 ____ GB/s 的系统级聚合带宽
假设 switch chip 提供的单个 Port 可以提供 28GB/s 的通信带宽
该问题直接查阅华为 CloudMatrix 384 的白皮书即可得到答案。
10. Cache 行为分析
假设我们需要进行一个矩阵乘法 。
测试环境
为了简化分析,假设:
| 参数类型 | 配置 |
|---|---|
| 数据类型 | double (8 Bytes) |
| L1 Cache 大小 | 4KB (4096 Bytes) |
| 相联度 | 直接映射 (Direct Mapped, E=1) |
| 块大小 | 64 Bytes ( 1 个 Cache Line 可存 8 个 double ) |
| 矩阵规模 | A, B, C 均为 64×64 的方阵 (N=64) |
| 存储方式 | 数组按行优先存储 |
| 内存对齐 | A, B, C 的起始地址均对齐到 Cache 的起始 Set |
代码实现
1 | // 假设变量 sum 已优化到寄存器中,忽略 C 的访存影响 |
问题 10.1
我们试图分析上述代码中最内层循环 Loop 3 对矩阵 的访存行为。
已知 Cache 总共有 个 Set 。
在计算
的过程中(即一次完整的 Loop 3 ),关于
的 Cache Miss Rate (不命中率),下列说法正确的是:
| 选项 | 描述 |
|---|---|
| A | 12.5% - 这里有良好的空间局部性,每 8 个 double 只有 1 次 Miss |
| B | 25% - 虽然是列优先访问,但 Cache 够大,只有冷不命中 |
| C | 约 50% - A 和 B 互相打架(冲突),导致一半的数据被驱逐 |
| D | 100% - 发生了严重的 Cache Thrashing (抖动),每次读取都是 Miss |
💡 提示:计算一下访问 和 时的内存地址差值( Stride ),以及它们映射到的 Set Index 的跨度。
正确答案是 D 。
解释如下:
矩阵 B 是按行优先存储的,因此访问 B[k][j] 时, k 的变化会导致访问的内存地址以列为单位跳跃。
计算地址差值( Stride ):
每次访问 B[k][j] 时,地址增加 512 Bytes ,而每个 Cache Line 大小为 64 Bytes ,因此每次访问都会跨越多个 Cache Line 。
计算 Set Index 的跨度:
因为 Cache 有 64 个 Set ,跨度为 8 意味着每次访问都会映射到不同的 Set ,但由于 k 从 0 到 63 ,共有 64 次访问,这些访问会循环映射到同一组 Set 上,导致频繁的冲突和驱逐。
最终结果是每次读取 B[k][j] 都会导致 Cache Miss ,即 Cache Thrashing 。
问题 10.2
为了进一步提升矩阵乘法的效率,我们决定使用分块技术。你将矩阵分成了 的小块( Block Size = 8 )。
1 | // 8x8 分块优化演示 |
针对一个 的 矩阵子块(假设该子块已预加载),在处理该子块内部的计算时,关于其在 L1 Cache 中的状态,下列分析正确的是:
| 选项 | 描述 |
|---|---|
| A | 一个 8×8 的子块大小为 512 Bytes ,远小于 Cache 大小,因此完全没有冲突,所有数据都能驻留在 Cache 中 |
| B | 尽管子块很小,但由于 B 的原始列宽( Stride )很大,导致子块内的 8 行数据全部映射到了同一个 Set 中,依然存在严重的冲突 |
| C | 子块内的 8 行数据分别映射到了 8 个不同的 Set 中( Set 索引间隔为 8 ),且在子块计算期间不会发生自我冲突( Self-Conflict ) |
| D | 分块主要是为了利用 L2/L3 Cache ,对这么小的 L1 Cache (4KB) 来说, 8×8 的分块没有任何意义 |
正确答案是 C 。
解释如下:
一个 8×8 的子块大小为:
该子块的大小( 512 Bytes )确实远小于 L1 Cache 大小( 4KB ),但关键在于访问模式。
在处理该子块时,访问 B[k][j] 时, k 的变化会导致访问的内存地址以列为单位跳跃。
计算 Set Index 的跨度:
因此,子块内的 8 行数据分别映射到了 8 个不同的 Set 中,且在子块计算期间不会发生自我冲突( Self-Conflict )。
分块技术有效地利用了 Cache 的空间局部性,减少了冲突,提高了数据的命中率。